Ruby 线程基础
本文是学习笔记,学习过程中主要阅读和参考了以下资料,记录的代码片断也来自以下链接。部分代码稍作了修改。最后那个链接虽然有些标题党,但是内容很值得一看:
- Working with Ruby Threads
- Does the GIL Make Your Ruby Code Thread-Safe?
- Ruby concurrency: in praise of the mutex
- 99%的人没弄懂volatile的设计原理,更别说灵活运用了
如果你想要靠并发提高性能,就得开启更多的进程,Ruby 社区多年以来一直是这么做的。
但是线程的内存开销比进程小得多,因为同一进程内的线程可以共享内存,而进程之间并不共享内存。而使用线程代价是:你的程序必须是线程安全的。
我们的代码始终运行在线程中。在没有主动创建线程的情况下,代码运行在主线程中。
主线程与其它线程的一个主要区别是,当主线程退出时,其它线程会立即退出,并且当前 Ruby 进程也会退出。
Thread.main 用于获取主线程。Thread.current 用于获取当前线程。
线程的执行
多线程中最重要的概念就是共享地址空间,这是多线程的优点,同时也是多线程编程困难的原因。
1.8 及之前版本的 Ruby, 一直使用的是“绿色线程”,即 Ruby 虚拟机自己管理的线程。Ruby 1.9 之后,一个 Ruby 线程直接映射到一个操作系统线程(当你在 Ruby 进程里创建线程时,可以用 top 命令看到它),由操作系统调度。
为公平起见,线程调度器会在任意时刻挂起当前线程,切换到另一个线程执行程序。之后在某个时间,调度器又会切回到之前的线程继续执行。这个动作叫做“上下文切换”(context switching)。
下面的代码演示了“上下文切换”可能引起的问题。其中的 ||= 不是原子性操作,因此不是线程安全的。所谓“原子操作”,是指在它执行完成之前不会被上下文切换中断的操作。
@results ||= Queue.new
@results << status
以上代码大约等价于:
if @results.nil?
temp = Queue.new
@results = temp
end
@results << status
因此 ||= 有可能造成在一个线程执行完 @results.nil? 的判断之后挂起,切换到另一个线程。另一个线程执行完整个赋值步骤并往 @results 里塞数据之后再切换回来,这样便造成给 @results 二次赋值。第一次赋值后塞进的数据被丢掉。这种情况下,我们说这里产生了“竞态条件” (race condition).
要解决 ||= 引起的线程安全问题,就应该在初始化公共资源时避免使用它,改成在构造方法里或者用其它方式初始化该变量。
线程的生命周期
Thread.new 用于创建一个线程,block 参数内的代码块即为新线程里运行的代码。
join 方法的调用会让当前线程等待被调用 join 方法的那个线程实例执行完毕,之后接着执行当前线程。
两个不同的线程当中,任意一个线程抛出异常,都会中止自身线程,但都不影响另一个线程继续执行。但是如果在一个线程里调用了另一个线程的 join 方法,则前者会受后者未处理异常的影响。以下两段代码的执行结果会有所不同:
# 代码片断 1
3.times do
Thread.new { raise 'error' }
end
sleep 1
puts 'end'
# 代码片断 2
3.times.map do
Thread.new { raise 'error' }
end.each(&:join)
sleep 1
puts 'end'
value 方法与 join 方法类似,但它会返回线程的执行结果。
thread = Thread.new do
400 + 5
end
puts thread.value #=> 405
status 方法可以获取线程的状态。Ruby 为线程定义了如下几种状态:
- run: 表示线程正在运行;
- sleep: 表示线程正在睡眠、被 mutex 阻塞或者在等待 IO.
- false: 表示线程执行完毕,或者被成功地杀掉;
- nil: 表示线程内部抛出了异常并且未被捕获和处理;
- aborting: 线程正在退出
adder = Thread.new do
# Here this thread checks its own status.
Thread.current.status #=> 'run'
2 * 3
end
puts adder.status #=> 'run'
adder.join
puts adder.status #=> false
Thread.stop 方法可以让线程睡眠,之后线程调度器会去调度其它线程。wakeup 方法可以将其唤醒。注意前者是类方法。
thread = Thread.new do
Thread.stop
puts 'Hello there'
end
# wait for the thread to trigger its stop
begin
puts thread.status
end until thread.status == 'sleep'
thread.wakeup
thread.join
Thread.pass 方法直接让调度器去调度其它线程,但当前线程自身并不睡眠——也因此调度器并不一定会照字面上的意图去调度其它线程。
raise, kill 方法:不要使用。
并发 != 并行
两个线程同时分别开始干两件事情,这叫做并发。但在单核 CPU 的环境下,两个并发线程的代码是交替执行的,并不算并行;而在多核心 CPU 的环境下,两个并发线程的代码有可能真正意义上的“同时”进行,这才叫并行。但这也只是有可能,具体是不是并行,还要看线程调度器如何调度。因此,并发的代码是否能够并行,这不是程序员的代码能够控制的。
GIL 和 MRI
因为 GIL 的存在,MRI 允许 Ruby 代码的执行并发,但不允许并行。JRuby 和 Rubinius 没有 GIL,所以允许代码并行执行。
GIL (Globel Interpreter Lock) 有时又被叫做 GVL (Global VM Lock), 是一个全局锁——每个 MRI Ruby 进程有且只有一个 GIL. 也就是说,进程中的所有线程共享一个 GIL. 只有正在执行的那个线程能够获得这个锁,其它线程则会等待,直到轮到它们获取 GIL. 因此,MRI Ruby 里不存在并行。
require 'digest/md5'
3.times.map do
Thread.new do
Digest::MD5.hexdigest(rand)
end
end.each(&:value)
以上代码创建了 3 个线程用来生成一个随机数的 MD5 值。因为 3 个线程都想要执行,所以他们都会去尝试获取 GIL. GIL 是用互斥锁 ( mutex ) 实现的。操作系统会保证在任意时刻只有一个线程持有互斥锁,其余线程则进入睡眠状态,直到互斥锁被释放,再次变得可用。
获得 GIL 的线程(这里我们称之为线程 A)此时开始执行代码,具体执行多久由 MRI 内部实现。一段时间之后,该线程释放 GIL, 线程调度器唤醒另外两个线程,开始争夺 GIL. 系统内核会决定谁将获得 GIL. 这时,线程 A 和另一个未获取到 GIL 的线程进入睡眠状态。
特殊情况:阻塞 IO
GIL 能够阻止 Ruby 代码并行执行,但是阻塞 IO 执行的不是 Ruby 代码:
require 'open-uri'
3.times.map do
Thread.new do
open('http://zombo.com')
end
end.each(&:value)
这段代码中创建了 3 个线程发出 HTTP 请求,MRI 在遇到阻塞 IO 时不会让线程继续占用 GIL, 这样其它线程就可以获得 GIL 以继续执行 Ruby 代码,于是就有第二个、第三个线程跟着执行到此处,同时等待着 HTTP 的响应。
一些误解
GIL 的存在并不能保证线程安全。比如有下面一段代码:
@counter = 0
5.times.map do
Thread.new do
temp = @counter
temp = temp + 1
@counter = temp
end
end.each(&:join)
puts @counter
在 MRI 环境中,几乎不会出现什么错误,但是如果在线程里插入一句 puts, 情况就不一样了。如上面所说,阻塞 IO 会让线程释放 GIL, 这样就可能出问题:
@counter = 0
5.times.map do
Thread.new do
temp = @counter
temp = temp + 1
puts 'message'
@counter = temp
end
end.each(&:join)
puts @counter
多少线程才算太多?
1. 操作系统的限制
1.upto(10_000) do |i|
Thread.new { sleep }
puts i
end
上面这段代码,在 OS X 系统当中,只能输出到 2000 左右,随后便会抛出 ThreadError 异常中断执行。因为 OS X 对单个进程的最大线程数作出了限制。但在 Linux 当中,这段代码可以完整地执行完。
2. IO 密集型的代码
网络请求、日志输出等任务是属于 IO 密集型的任务,在处理这类任务时,提升网络速度、磁盘读写速度可以很大地提高整体性能。如果你的代码是 IO 密集型的,线程越多运行得可能越快,而且往往线程数多于 CPU 核心数是有作用的。但也不是越多越好。比如下面这段代码:
require 'benchmark'
require 'net/http'
URL = URI('http://www.baidu.com/')
ITERATIONS = 30
def fetch_url(thread_count)
threads = []
thread_count.times do
threads << Thread.new do
fetches_per_thread = ITERATIONS / thread_count
fetches_per_thread.times do
Net::HTTP.get(URL)
rescue => e
retry
end
end
end
threads.each(&:join)
end
Benchmark.bm(20) do |bm|
[1, 2, 3, 5, 6, 10, 15, 30].each do |thread_count|
bm.report("with #{thread_count} threads") do
fetch_url(thread_count)
end
end
end
在我的电脑上运行结果如下:
user system total real
with 1 threads 6.610000 0.160000 6.770000 ( 4.259840)
with 2 threads 3.630000 0.060000 3.690000 ( 2.390968)
with 3 threads 1.000000 0.040000 1.040000 ( 1.494768)
with 5 threads 1.190000 0.060000 1.250000 ( 1.392179)
with 6 threads 0.790000 0.030000 0.820000 ( 0.989476)
with 10 threads 0.830000 0.030000 0.860000 ( 0.673836)
with 15 threads 0.940000 0.020000 0.960000 ( 0.654832)
with 30 threads 0.780000 0.090000 0.870000 ( 0.653245)
基本上 10 个线程就已经达到最佳性能。再往上加线程数就不划算了,因为线程的创建也有开销——虽然比进程开销小。因此,到底多少线程合适,还得视具体情况而定。如果网络延迟较高,可能会需要更多的线程达到最佳性能。比如我把上面代码中的网址换成一个俄罗斯的网址,执行结果就变成:
user system total real
with 1 threads 17.030000 0.340000 17.370000 ( 22.337289)
with 2 threads 5.110000 0.140000 5.250000 ( 10.433548)
with 3 threads 2.380000 0.070000 2.450000 ( 6.352316)
with 5 threads 1.860000 0.090000 1.950000 ( 4.780961)
with 6 threads 2.030000 0.070000 2.100000 ( 3.578058)
with 10 threads 1.890000 0.030000 1.920000 ( 2.331823)
with 15 threads 1.530000 0.060000 1.590000 ( 1.875414)
with 30 threads 1.470000 0.050000 1.520000 ( 1.350604)
另外,这段代码无论是用 MRI Ruby 还是 JRuby, 运行结果都差不多,也说明了阻塞 IO 会让线程释放 GIL.
3. CPU 密集型的代码
压缩/解压、加密、计算散列值以及一些非常复杂的数学计算之类的任务属于 CPU 密集型任务。在处理这类任务时,CPU 频率的提升能够提高整体性能。线程数不超过核心数时,线程越多运行越快。线程数超过核心数之后,性能不再提升,反而可能因为线程切换的开销有所下降。
require 'benchmark'
DIGITS = 30
ITERATIONS = 24
def fibonacci(n)
return n if (0..1).include? n
(fibonacci(n - 1) + fibonacci(n - 2))
end
def calculate_fib(thread_count)
threads = []
thread_count.times do
threads << Thread.new do
iterations_per_thread = ITERATIONS / thread_count
iterations_per_thread.times do
fibonacci(DIGITS)
end
end
end
threads.each(&:join)
end
Benchmark.bm(20) do |bm|
[1, 2, 3, 4, 6, 8, 12, 24].each do |thread_count|
bm.report("with #{thread_count} threads") do
calculate_fib(thread_count)
end
end
end
这段代码在我的四核 CPU 上执行的结果如下:
user system total real
with 1 threads 5.920000 0.050000 5.970000 ( 5.102896)
with 2 threads 4.980000 0.010000 4.990000 ( 2.444580)
with 3 threads 4.880000 0.000000 4.880000 ( 1.626186)
with 4 threads 5.380000 0.000000 5.380000 ( 1.355286)
with 6 threads 7.070000 0.000000 7.070000 ( 1.336971)
with 8 threads 10.130000 0.030000 10.160000 ( 1.317468)
with 12 threads 9.990000 0.010000 10.000000 ( 1.319313)
with 24 threads 10.400000 0.020000 10.420000 ( 1.373466)
看起来线程数与核心数相同时就接近最佳性能了。
在真实系统当中,很少有纯粹的 IO 密集或者 CPU 密集型程序。拿常见的 web 服务来举例,当它在接收客户端请求、返回响应内容、读写数据库时,做的就是 IO 密集型的事情;当它在解析数据、进行数学计算、渲染 HTML, JSON 的时候,做的就是 CPU 密集型的工作。所以,到底多少线程是合适的,还是需要具体地测试才能得出结论。
用 Mutex 保护数据
Ruby 标准库当中的 Array 不是线程安全的:
shared_array = Array.new
mutex = Mutex.new
10.times.map do
Thread.new do
1000.times do
shared_array << nil
end
end
end.each(&:join)
puts shared_array.size
以上代码将会产生类似以下输出:
$ ruby code/snippets/concurrent_array_pushing.rb
10000
$ jruby code/snippets/concurrent_array_pushing.rb
7521
$ rbx code/snippets/concurrent_array_pushing.rb
8541
$ _
这里可以使用 Mutex (互斥锁)来保证正确的结果:
shared_array = Array.new
mutex = Mutex.new
10.times.map do
Thread.new do
1000.times do
mutex.lock
shared_array << nil
mutex.unlock
end
end
end.each(&:join)
puts shared_array.size
Mutex 在这里的使用,告诉了线程调度器在当前代码块执行完之前别切换线程。其中 lock ... unlock 代码块也可以改成这样:
mutex.synchronize do
shared_array << nil
end
Mutex 和内存可见性
线程 A 在持有 mutex 并对变量进行了修改,线程 B 直接读取该变量的话,有可能读到的是修改之前的值。
我们知道在计算机硬件结构当中,早期的 CPU 是直接读写内存的。后来为了提升性能,CPU 加上了高速缓存(一级缓存、二级缓存等),直接在高速缓存里读写数据,运算完成后再把数据同步到内存。在单核时代这并不会有什么问题,但在多核 CPU 中会有内存一致性的问题,因为不同 CPU 核心使用的是独立的一、二级缓存,并不共享。
因此,即使用了 mutex, 线程 B 也有可能在该变量未同步到内存时读取了它的值,造成我们不想要的结果。为了避免这个问题,需要用到一个叫作“内存屏障”的东西,它可以对内存操作进行排序约束,让变量的写操作执行完毕并同步到内存之后再开始读操作,从而防止读操作读到旧数据。
Ruby 的 Mutex 在充当原子性锁的同时,也是一个内存屏障。只要修改一下变量读取的方式,你就可以利用好这个内存屏障。下面是一个例子:
# visibility.rb
mutex = Mutex.new
flags = [false, false, false, false, false, false, false, false, false, false]
threads = 50.times.map do
Thread.new do
10000.times do
puts flags.to_s
mutex.synchronize do
flags.map! { |f| !f }
end
end
end
end
threads.each(&:join)
执行以上代码,你会得到类似下面的结果:
$ ruby visibility.rb > visibility.log
$ grep -Hnri 'true, false' visibility.log | wc -l
3151
$ _
这表示有线程读取到了其它线程未完全同步到内存的数据。想要避免这个问题,只需要把读取 flags 的代码也放在 mutex.synchronize 的代码块内即可:
...
mutex.synchronize do
puts flags.to_s
end
mutex.synchronize do
flags.map! { |f| !f }
end
...
Mutex 的性能
Mutex 在关键的地方保护着数据在同一时刻只能被一个线程修改,其实 GIL 就是一个 mutex.
但像上面这样一来,并行变成串行,执行速度就明显更慢了。因此,持有 mutex 的代码块应该尽可能的小。因为只需要在取值的时候持有 mutex, 可以把 puts 这样可以并行执行的阻塞 IO 操作移出来,上面的代码可以优化如下:
...
flags_string = nil
mutex.synchronize do
flags_string flags.to_s
end
puts flags_string
mutex.synchronize do
flags.map! { |f| !f }
end
...
在我的 x220 笔记本上,这段代码的执行时间由 20 秒减少到了 10 秒,直接少了一半。要是这里用的不是 puts 而是发起一个网络请求,那么这个优化的收益会更可观——或者换句话说,未优化的代码的执行速度会极度地慢,下面就是一个例子:
require 'thread'
require 'net/http'
mutex = Mutex.new
@results = []
10.times.map do
Thread.new do
mutex.synchronize do
response = Net::HTTP.get_response('dynamic.xkcd.com', '/random/comic/')
random_comic_url = response['Location']
@results << random_comic_url
end
end
end.each(&:join)
puts @results
如果把 HTTP 请求移出 synchronize 块,就能极大地提升性能。另外如果这里的 @results 用的是 Queue 而不是 Array, 就没有 mutex 什么事了。因为 Queue 本身是线程安全的。
死锁
线程 A 在执行代码时持有了 mutex_a, 线程 B 在执行代码时持有了 mutex_b. 这时,线程 A 需要访问线程 B 正在访问的资源,尝试去获取 mutex_b, 而线程 B 也需要访问线程 A 正在访问的资源,尝试去获取 mutex_a. 此时因为线程 A 没有执行完毕,mutex_a 就没有释放;同样因为线程 B 也没有执行完毕,mutex_b 也就没有释放。线程 A 和线程 B 都在等待对方的 mutex 释放,这种状态就被称为死锁。
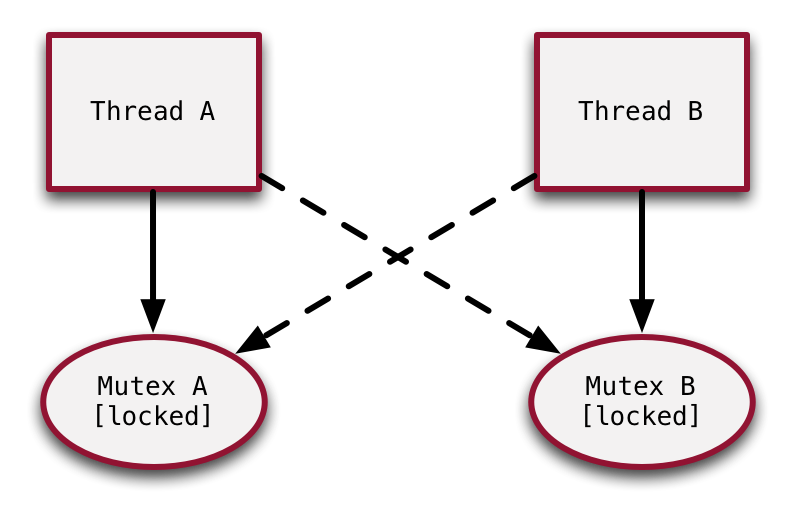
由此可以知道,死锁通常发生在线程需要获取多个 mutex 的时候。
Ruby 的 Mutex 提供了一个 try_lock 的方法,该方法的用法跟 lock 一样,区别在于 try_lock 在 mutex 不可用时不会一直等待,而是返回 false. 如果获取到 mutex, 则返回 true.
但如果只是在 try_lock 返回 false 后不停重试,并不解决问题,程序只是由死锁状态变成了死循环。正确的做法是在 try_lock 失败之后,线程各自释放掉自己的 mutex 重新从头开始执行,期待通过多线程本身的不确定性,使之在重新开始后能够执行成功。
即便如此,过程中也可能有不确定次数的重试,而且似乎很多时候,代码是不可以重复执行的,否则会产生预期以外的数据(这么说这个 try_lock 方案根本不解决问题)。
一个更好的方案是定义一个 mutex 层级,或者换句话说:当两个线程都需要获取多个 mutex 的时候,确保它们获取这些 mutex 的顺序是一致的。这样便可以在任何时候避免死锁。
通过条件变量给线程发信号
条件变量 (Condition Variable) 可以用于线程间发送事件通知。ConditionVariable 的 wait(mutex) 方法会让当前线程释放 mutex 并进入睡眠状态,signal() 方法可以唤醒在 ConditionVariable 实例上等待的一个线程:
require 'thread'
require 'net/http'
mutex = Mutex.new
condvar = ConditionVariable.new
results = Array.new
Thread.new do
10.times do
uri = URI('https://dynamic.xkcd.com/random/comic/')
response = Net::HTTP.get_response(uri)
random_comic_url = response['Location']
mutex.synchronize do
if random_comic_url && !random_comic_url.empty?
results << random_comic_url
condvar.signal # Signal the ConditionVariable
end
end
end
end
10.times.map do
Thread.new do
mutex.synchronize do
while results.empty?
condvar.wait(mutex)
end
url = results.shift
puts "You should check out #{url}"
end
end
end.each(&:join)
这段代码中比较让人疑惑的地方在于 while results.empty?, 似乎这里使用 if results.empty? 就可以了。但实际上 ConditionVariable#signal 只是发送事件通知,告诉等待着的线程“有另一个线程往 results 里塞了一条数据”,并不保证其它事情——比如说“这条数据会一直等着你去取”,很可能该数据会被其它线程取走。
ConditionVariable 还有一个 broadcast() 方法,用于唤醒在当前 ConditionVariable 实例上等待的所有线程:
mutex.synchronize do
if random_comic_url && !random_comic_url.empty?
results << random_comic_url
condvar.broadcast if results.size == 10
end
end
下面是结合使用 Mutex 和 ConditionVariable 实现的一个线程安全的 BlockingQueue:
require 'thread'
class BlockingQueue
def initialize
@storage = Array.new
@mutex = Mutex.new
@condvar = ConditionVariable.new
end
def push(item)
@mutex.synchronize do
@storage.push(item)
@condvar.signal
end
end
def pop
@mutex.synchronize do
while @storage.empty?
@condvar.wait(@mutex)
end
@storage.shift
end
end
end
前面已经提到过,实际上 Ruby 自带了一个 Queue 类型,这是 Ruby 中唯一一个线程安全的数据结构类型。 require 'thread' 之后便可以使用。其它数据结构包括 Array, Hash 等,都不是线程安全的,即使在 JRuby 的实现当中也一样。因为线程安全相关的代码会降低其在单线程程序中的性能。如果非要用线程安全的数据结构不可,可以考虑使用 thread_safe 这个 Gem.