根据参考文章做了一些简要的笔记和概括
更多请参考引用部分
一、并发(Concurrency)和并行(Parallel)的区别
并发和并行是相近的概念。和并发所描述的情况一样,并行也是指两个或多个任务被同时执行。但是严格来讲,并发和并行的概念并是不等同的,两者存在很大的差别。
简单的一张图可以简单明了的理解 并行和并发
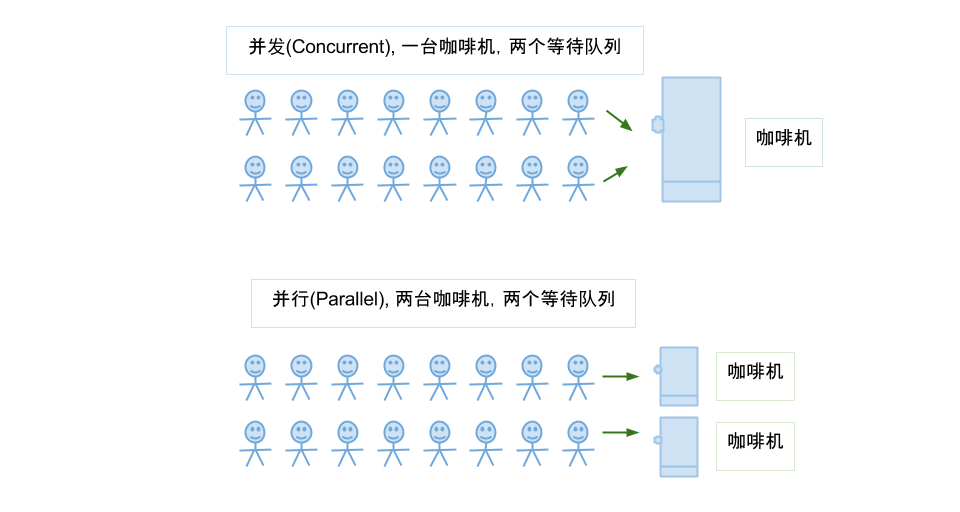
直观来讲,并发是两个等待队列中的人同时去竞争一台咖啡机。现实中可能是两队人轮流交替使用、也可能是争抢使用——这就是竞争。
而并行是每个队列拥有自己的咖啡机,两个队列之间并没有竞争的关系,队列中的某个排队者只需等待队列前面的人使用完咖啡机,然后再轮到自己使用咖啡机。
可以这样理解:
并发是一个处理器同时处理多个任务,而并行多个处理器或者是多核的处理器同时处理多个不同的任务。前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生。
二、进程
进程(英语:process),是指计算机中已运行的程序。进程曾经是分时系统的基本运作单位。
它包括一些具体内容比如 独立的内存、系统中独立的PID等。
在时分复用系统中,操作系统在不同的进程之间进行上下文切换,来达到 “并发”的效果。
我们只需要简单的知道,他是一个基本单位,它的切换在操作系统之中,并且他的上下文切换相当的占用时间、和占据内存。
Ruby的一些框架是通过 进程+fork的方式工作的,比如 Sidekiq。以fork进程工作的会存在一切缺点:
- 切换上下文时间相对较长
- 上下文的内存相对较大
- fork的子进程,当父进程死掉,会成为僵尸进程,等待系统回收(占用内存)
三、线程
线程(英语:thread)是操作系统能够进行运算调度的最小单位。大部分情况下,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
然后操作系统也会在进程之中,调度内部的线程,假设是多个线程,会在其中切换不同线程执行。
相对进程,线程弥补了进程切换的一切问题
3.1 多线程的意义
多线程的优点
- 共享内存
- 切换上下文时间段
- 占用内存少
- 父进程关闭,子进程自动关闭
- 任务分片
多线程的意义和操作系统的时间切片其实是相当的。
如果没有多线程,我们的程序会是如何?
以小汽车移动举例子,如下两个颜色的小汽车,A、B,如果我们想移动他们,只能顺序移动。

如果是支持多线程程序,A、B 可以同时移动。比如一些游戏的坦克大战多个坦克运动;比如你可以在一个程序中既能聊天还能播放音乐比如浏览器等等。

3.2 线程存在的问题
- 竞争带来的复杂问题,涉及到锁
就像前面,并行并发 提到的咖啡机模型,多个线程,他们在使用CPU会产生竞争问题,分配给谁?一般是交给操作系统来调度。但是当他们去访问同一个内存读写的时候,由于无法保证顺序,常常会出现问题——也就是线程不安全。
举个Ruby的例子
a = 0
threads = (1..10).map do |i|
Thread.new(i) do |i|
c = a
sleep(rand(0..1))
c += 10
sleep(rand(0..1))
a = c
end
end
threads.each { |t| t.join }
puts a
这段代码要实现的功能很简单,只是把变量a累加10次,每次加10,并且开了10个线程去完成这个任务。正常情况下我们期望的值是a == 100,然而事实却是
> ruby a.rb
10
> ruby a.rb
10
> ruby a.rb
30
> ruby a.rb
20
出现这种情况的原因是,当我们的操作执行到一半的时候其他线程介入了,导致了数据混乱。这里为了突出问题,我们采用了sleep方法来把控制权让给其他线程,而在现实中,线程间的上下文切换是由操作系统来调度,我们很难分析出它的具体行为。
现实中为了解决问题,我们需要加锁
a = 0
mutex = Mutex.new
threads = (1..10).map do |i|
Thread.new(i) do |i|
# 加锁
mutex.synchronize do
c = a
sleep(rand(0..1))
c += 10
sleep(rand(0..1))
a = c
end
end
end
threads.each { |t| t.join }
puts a
这样可以保证结果
> ruby a.rb
100
> ruby a.rb
100
四、GIL
在Python、Ruby中都存在一个东西叫做 GIL(全局解析器锁)。
GIL起到什么作用呢,以Ruby的MRI解释器为例,存在GIL的MRI只能够实现并发,并无法充分利用CPU的多核特征,实现并行任务,进而减少程序运行时间。
在MRI里面线程只有在拿到GIL锁的时候才能够运行,即便我们创建了多个线程,本质上也就只有一个线程实例能够拿到GIL,如此看来某一时刻便只能有一个线程在运行。
可以考虑下面这样的场景:
老师给小蓝安排了除草任务,小蓝为了加快速度呼唤了好友小张,然而除草任务需要有锄头才能进行。为此,即便有好友相助但锄头却只有一把所以两个人无法同时完成除草的任务,只有拿到锄头使用权的一方才能够进行除草。这把锄头就像是解析器中的GIL,把小张跟小蓝想象成被创建的两个线程,当两个人的工作效率一样的时候,受限于锄头这个约束并无法同时进行除草任务,只能够交替使用锄头,本质上并不会减少工作时间,反而会在换人的时候(上下文切换)耗费掉一定的时间。
在一些场景下创建更多的线程并不能真正地减少程序的运行时间,反而有可能会随着进程数量的增加而增加切换上下文的开销,从而导致程序变得更慢。
五、协程
线程是由操作系统来控制切换的。而系统的切换是一种通用的策略,在一些场景下会没必要的浪费时间。
协程 就是一种让程序员去手动切换,这个过程就像 线程之间 可以互相协作 来完成任务,避免不必要的切换。具体如何切换、交给谁,这个根据实际的任务,程序员来判断。
比如 小明做 语文、数学、英语三节课。系统调度采用的是通用策略,他可能的选择是在三个任务之间均衡。
系统不停地在切换,实际上这种切换浪费了大量的时间。

我们现实中会这样做,因为这样是更优的选择。这样就减少了无意义的切换提高了效率。

比如IO,当我们遇到IO的时候,有几种情况:
-
单线程就只能等待IO完成再继续。
-
系统无差别调度,工作线程和IO线程之间切换。
-
协程手动调度,遇到IO之后,直接转移控制权给其他代码。 这样可以有目标的去编写非阻塞、吞吐量大的程序。
六、解放GIL充分利用多核
以Ruby为例,想要去除 4个人干活 共用一个锄头的 GIL的尴尬事情。可以选择使用去除GIL的解释器。
除了GIL的实现,其中包括Rubinius 以及 jruby他们的底层分别用的是C++以及Java实现的,除了去除GIL锁之外,他们还做了其他方面的优化。某些场景下他们都有着比MRI更好的性能。
这就需要你的程序里面避免出现竞争条件。
一些好的例子是 比如Python的Flask框架,他使用对不同线程ID建立起一个map保存request、response上下文巧妙地实现了线程隔离,在处理web的这块可以做到线程安全。
还有一些专门解决多线程的模型
6.1 Actor模型 Ractor(合成词Ruby Actor)并发模型
Ractor 像 Go、Erlang的并发模型看齐
具体的实现
6.2 Guilds 并发模型
6.3 事件驱动模型
事件驱动这是一个像JavaScript的原理的一个实现,使用了单线程eventloop的方式进行工作,可以进行大量的IO,而不需要担心线程问题。
具体实现
6.4 进程+fork, 让操作系统完成调度
这是一种补充,这种方案扎根于Unix、Linux操作系统。
可以充分利用多核新。可以通过 标准库 实现。但是会比 上述线程方案要重。因为进程的内存是隔离的所以不会竞争。
原理可以参考
具体实现
大名鼎鼎的 unicorn
puma也使用了这个模型。但是puma同样也拥有多线程
参考
并发并行部分
进程部分
线程部分
GIL部分
协程部分
其他
-
Ruby Puma 允许在每个进程中使用多线程, 每个进程都有各自的线程池. 大部分时候不会遇到上面说的竞争问题, 因为每个 HTTP 请求都是在不同的线程处理.
-
Python的Flask设计巧妙在于使用一个map做到了线程隔离,每个线程都有独立的request、response上下文也可以做到巧妙地不同现场处理。
-
Python的Tornado 使用了协程来写出非阻塞的吞吐量更高的web server。
-
Ruby中去除GIL的解释器:除了GIL的实现,其中包括Rubinius 以及 jruby他们的底层分别用的是C++以及Java实现的,除了去除GIL锁之外,他们还做了其他方面的优化。某些场景下他们都有着比MRI更好的性能。
感谢,看完这篇文章收获很大。