按照习惯起个调
作为程序员,经常会在编程语言、操作系统、网络以及文本编辑等多个层面遇上字符集或者字符编码的问题,尽管一般都能快速通过搜索引擎找到解决方案,但是对于这种字符集以及其相关的字符编码格式的知识,倒是未曾系统梳理。恰逢近期有了一些收获,趁热记录分享下。
从 Unicode 和 UTF-8 说起
对于类 Unix 操作系统(比如 Mac OS 以及 Linux 操作系统等)的用户来说,会更多地接触 UTF-8 编码格式,我也是其中一个。而我过往总是容易跟另一个词—— Unicode 混淆,所以,当我们在讨论 UTF-8 和 Unicode 的时候,我们在讨论什么?
Unicode 字符集简介
当我们说 Unicode 的时候,是在讨论一种字符集(character set)。Unicode 翻译成中文叫“统一码”,是一种可以简单理解为收录了世界上所有语言的文字和符号的全球标准。大家知道,英语的基本组成元素是 26 个英文字母加上各种标点符号;而汉语的文字则相对繁杂,大量汉字,每个文字都有各自的拼音,拼音里还要区分音调,这里提到的汉字、拼音、音调以及汉字自身的标点符号,跟英语的英文字母以及标点符号等,统统收录在了 Unicode 字符集中,而类似的,还有繁体中文、日文、韩文、俄罗斯语、越南语、泰语、蒙古语等等。
收录了这么多的字符,就会带来一个问题:怎么整理和编排记录这些内容呢?编号!类比在一些常见的场景中,当一个集体中包含很多的个体时,为了用一种统一且简单的方式区分,我们最容易想到的就是编号。比如,给班里的同学安排座位号,给学生安排学号,给员工安排工号,等等。
但是,计算机是不能直接理解十进制这种人类易于理解的数字的,它只能理解二进制的数值,所以,在计算机里,我们可以用编码(使用特定的二进制序列来表示一个特定的值)的方式来给这些字符和符号进行一一映射。目前 Unicode 实际应用版本 UCS-2 在计算机中使用了 2 个字节来编码一个字符,也就是 16 位的编码空间,在表示上,采用类如 U+???? 的形式,其中每个“?”都是一个十六进制数。注意,Unicode 还有个 4 字节编码版本,亦即 UCS-4,不在这里讨论。
以下是一些示例的 Unicode 字符及其对应编码:
| 字符 | 编码值 | 说明 |
|---|---|---|
| 牛 | U+725B | 汉字 |
| ù | U+00F9 | 拼音 u 的四声 |
| , | U+002C | 英文逗号 |
| , | U+FF0C | 中文逗号 |
| 😁 | U+D83D | emoji 表情:笑脸 |
| ⚔ | U+2694 | emoji 表情:剑 |
是不是挺有意思的?另外是否也注意到,同样是逗号,但是英文的逗号和中文的逗号,并不是同一个符号,哪怕看起来非常相似!相信很多初学编程的同学也都踩过在代码中输入了中文逗号导致代码编译出错的坑吧!
UTF-8 —— 一种变长的 Unicode 字符编码转换格式
上面 Unicode 的编码方式已经理解了,但是那还只是表示层面的,字符在计算机世界里,需要被传输和存储等,这种情况下又该设计呢?最简单的方式当然是直接原样使用每个字符的两个字节即可(事实上,UTF-16 即是这种思路),但是这种方式有两种问题:
- 对于英语这类只需要一些非常简单的字符就足够的语言来说,单字节的 ASCII 字符集(一种主要包含英文字母、数字和标点符号以及其他不可见字符的字符集,总共 128 个字符)刚好就足以使用,如果使用两个字节,无疑是浪费了一半的存储空间;
- 取决于具体的字节序,我们在存储和传输层面还得考虑字符编码的大端序或者小端序问题。
为了解决这些问题,UTF-8 应运而生。UTF 全称 Unicode Transformation Format,中文“Unicode 转换格式”。UTF-8 是一种变长编码,其最大的特点是完全兼容 ASCII 字符编码(本质上得益于 Unicode 完全兼容 ASCII 字符集),对于所有在 ASCII 字符集中出现的字符,其在 UTF-8 中也是使用完全一样的单字节表示,且二进制码值完全一致。
比如对比以下的字符,在 ASCII 字符集下以及 Unicode 字符集中,和使用 UTF-8 表示的值:
| 字符 | ASCII 码值(十进制表示) | Unicode 码值 | UTF-8 表示 |
|---|---|---|---|
| A | 65 | U+0041 | 0100 0001 |
| a | 97 | U+0061 | 0110 0001 |
| 9 | 57 | U+0039 | 0011 1001 |
| , | 44 | U+002C | 0010 1100 |
因此,对于需要存储或者传输包含有较多纯英文字符的文本,UTF-8 的这种格式能够节省更多的存储空间,比如磁盘或者内存以及网络带宽等!对于 UTF-8 的完整格式,稍后会有单独的一章来具体分析。
扩展:聊聊主要针对汉字的字符集——GBK 和 GB18030
上面聊到 UTF-8 优化了英文存储空间占用的问题,而且 Unicode 也是优先收录了各类西方语言的字符。那有没有专门针对我们汉字的方案呢?有的,GBK!
GBK,全称“汉字内码扩展规范”,全名为《汉字内码扩展规范(GBK)》1.0版。GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。所以 GBK 是一种主要收录汉字的字符集。
GBK 于 1995 年 12 月 15 日发布,而 2000 年国家质量技术监督局推出了 GB18030-2000 标准,用以取代 GBK,GB18030 完全兼容 GBK。而 GB18030 在本质上也算得上是一种 Unicode 的转换格式(UTF),只不过其转换要比 UTF-8 复杂得多,在此就不展开了。
稍后的一些例子中还会提到 GBK 或者 GB18030,这里仅作简单介绍,有个印象,大致知道是个啥即可。
UTF-8 编码格式分析
UTF-8 是一种变长(长度范围为 1-4 个字节)的字符编码格式,所以一个字符对应的字节长度,需要结合每个字节开头的比特位来确认,具体的规则是:
- 对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
- 如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
- 如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
- 如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
- 如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节。
所以,对于最长的 4 字节编码,其可表示的最大位数为 21(首字节剩余 3 位,后续 3 个字节,每个字节有 6 位, 3+3x6=21)。
上面的规则比较绕,为了方便理解,我们来列举下所有可能的比特序列:
① 单字节的情况,对应 ASCII:
0???????
② 双字节的情况,第一个字节必须 110 开头,第二个字节开头必须是 10,剩余 11 位用于编码:
110????? 10??????
③ 三字节的情况,第一个字节必须 1110 开头,第二、三个字节开头都必须是 10,剩余 16 位用于编码:
1110???? 10?????? 10??????
④ 四字节的情况,第一个字节必须 11110 开头,后续三个字节开头都必须是 10,剩余 21 位用于编码:
11110??? 10?????? 10?????? 10??????
一些示例的对应的 Unicode 字符及其对应的 UTF-8 编码:
| 类型 | Block | 字符 | Unicode 编码 | UTF-8 编码(16进制) | UTF-8 编码(二进制表示) |
|---|---|---|---|---|---|
| 单字节 | 基本拉丁字母 | a |
U+0061 | \x61 | 01100001 |
| 双字节 | 拉丁文补充集 | £ |
U+00A3 | \xC2\xA3 | 11000010 10100011 |
| 三字节 | 日文平假名 | の |
U+306E | \xE3\x81\xAE | 11100011 10000001 10101110 |
| 四字节 | 越南语 | 𦓡 |
U+D859 | \xF0\xA6\x93\xA1 | 11110000 10100110 10010011 10100001 |
而我们熟悉的常见的汉字使用的都是 3 字节的编码。
一些有趣的字符编码格式的例子
操作系统中的默认字符集和转换格式
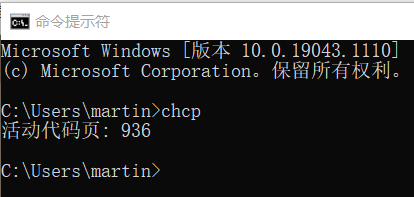
在 Windows 10 简体中文版系统中,通过在命令提示符程序中输入命令 chcp,可以查看到系统活动代码页为 936,对应的编码格式为GBK。
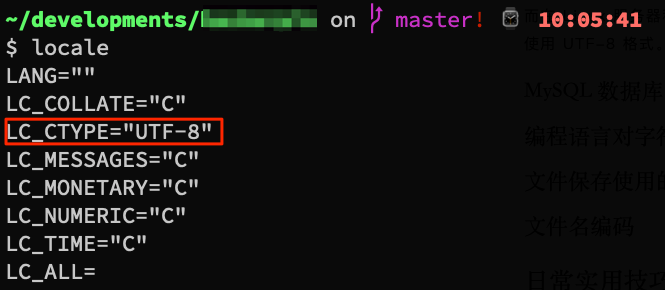
而在 Linux 服务器和我个人的 Macbook 电脑(操作系统 macOS Catalina 10.15.7)上,通过打印 LC_CTYPE 变量可以确认系统缺省使用 UTF-8 格式。
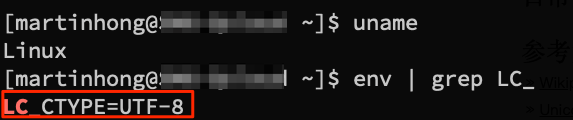
系统间的这种缺省字符编码格式的差异,往往会导致一个操作系统下编辑保存好的文件,到了另一个操作系统下就会出现乱码。除了文件内容乱码,也会存在文件名乱码的情况等,原因都是类似的。
MySQL 数据库中的字符集处理
有过 MySQL 数据库使用经验的同学一定对字符集的选择使用会有一些经验心得:
- 注意避免默认的
latin1字符集 - 如果需要支持 emoji 表情字符,还需要注意使用
utf8mb4字符集
这又是什么原因呢?历史原因!
首先,latin1 字符集是多字节字符编码技术之前的技术,在 MySQL 4.0 及更早之前的版本中缺省使用,可能出于向下兼容的因素,这个缺省逻辑一直保留到 5.7 版本,到了当前最新版 8.0 中,已经改为缺省 utf8mb4。
另外,MySQL 字符集在 MySQL 中有两套 UTF-8 的实现,大家容易想到的同名“utf8”的方案,每个字符最多占据 3 个字节的空间,是一套非完整的实现,因此 MySQL 后来将其正式名字改为“utf8mb3”,用以指示这是一套有缺陷的实现,而保留下来的“utf8”只不过是个别名而已了;如果需要完整的实现,需要使用“utf8mb4”。至于为什么会出现这种情况,根本原因还是历史。MySQL 在4.1 版本开始支持 UTF-8 编码格式,当时对 utf-8 的实现并未形成统一标准,而 MySQL 在其实现中限制了编码空间最多为3个字节,而 UTF-8 正式形成业界的标准化文档在这个事情之后。
编程语言对字符集的处理
来到编程语言层面,随着 utf-8 格式正式化以及发展,编程语言在字符集处理的方式上,在不同版本上也有一些有趣的历史。
- Ruby 2.0 以前的版本(不包含 2.0),如果需要指定源码的编码格式为 utf-8,需要在代码文件的开头加上魔法注释:
# encoding: utf-8 - 在 Python 3.0 以前的版本(不包含 3.0),如果需要指定源码的编码格式为 utf-8,需要在代码文件的开头加上魔法注释:
# -*- coding: utf-8 -*- - 在 Golang 中,由于这门语言本身比较新,没有这类在老版本代码中显式声明编码格式的需要
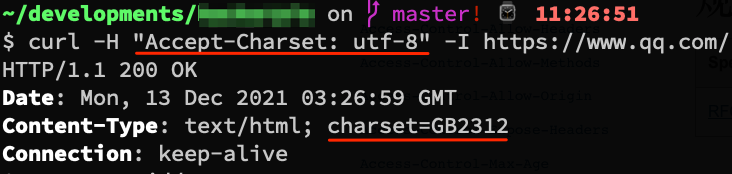
HTTP 中用 Accept-Charset 协商字符集
Accept-Charset 请求头用来告知(服务器)客户端可以处理的字符集类型。借助内容协商机制,服务器可以从诸多备选项中选择一项进行应用, 并使用 Content-Type 应答头通知客户端它的选择。
以下是一个实际的 HTTP 协议中协商 charset 的实际例子:
HTML 标记语言中指定字符编码
通常在 HTML 里声明 UTF-8 字符编码,使用如下:
<meta charset="utf-8">
总结
字符集和字符编码技术无处不在,通过诸多实际案例展示和原理分析,看到了其有趣且应用广泛的一面。希望这篇文章,能够帮助你更加系统全面地了解掌握对它的认识和应用!
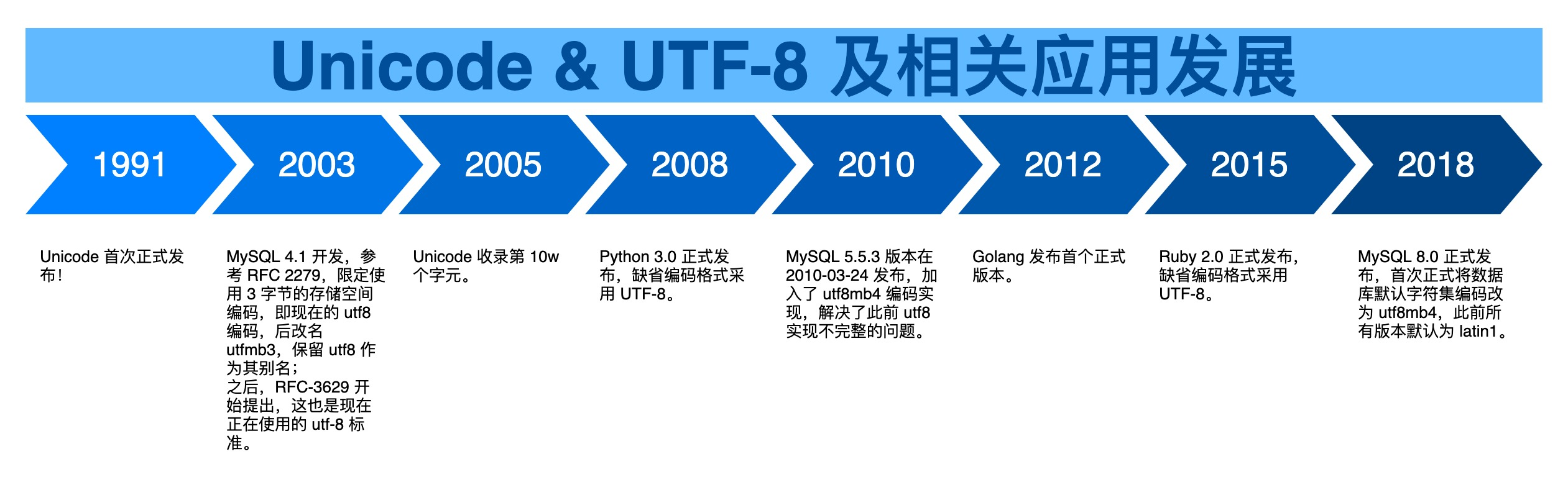
最后附上一张图,看下一些前面提到的例子中,比如编程语言或者数据库管理系统对 UTF-8 的应用和相伴发展概况,来结束这篇文章:
参考资料
- Wikipedia:Unicode
- Unicode 查询
- Wikipedia:ASCII
- Wikipedia:汉字内码扩展规范
- Wikipedia:GB18030
- Wikipedia:UTF-8
- UTF-8 encoder/decoder
- UTF-8 Sampler
- OSCHINA:在线进制转换
- StackOverflow: Unicode sample text file for testing for Unicode related problems?
- 云+社区:如何查看windows操作系统的默认编码?
- CSDN:查看windows与Mac的默认系统编码
- IBM: Changing your locale on Linux and UNIX systems
- StackOverflow: Why does MySQL use latin1_swedish_ci as the default?
- MySQL :: MySQL 5.7 Reference
- MySQL :: MySQL 8.0 Reference
- StackOverflow: Set UTF-8 as default for Ruby 1.9.3
- StackOverlfow: Working with UTF-8 encoding in Python source
- Wikipedia: MySQL
- Wikipedia: Python
- MDN: Accept-Charset
- MDN: Character encoding(字符编码)
- Medium: In MySQL, never use “utf8”. Use “utf8mb4”.
- MySQL 5.5 Release notes