在昨天的文章《一日一技:反爬虫的极致手段,几行代码直接炸了爬虫服务器》中,我讲到了后端如何使用gzip返回极高压缩率的文件,从而瞬间卡死爬虫。
大家都知道我的公众号风格,要得罪讨好就两边一起得罪讨好。昨天我帮了后端,今天我就帮帮爬虫。作为爬虫,如何避免踩中gzip炸弹?
最直接的方法,就是把你的爬虫隐藏起来,因为gzip炸弹只能在发现了爬虫以后使用,否则就会影响到正常用户。只要你的爬虫让网站无法发现,那么自然就不会踩中炸弹。
如果你没有把握隐藏爬虫,那么,请继续往下看。
查看gzip炸弹的URL返回的Headers,你会发现如下图所示的字段:

你只需要判断resp.headers中,是否有一个名为content-encoding,值包含gzip或deflate的字段。如果没有这个字段,或者值不含gzip、deflate那么你就可以放心,它大概率不是炸弹。
值得一提的是,当你不读取resp.content、resp.text的时候,Requests是不会擅自给你解压缩的,如下图所示。因此你可以放心查看Headers。:

那么,如果你发现网站返回的内容确实是gzip压缩后的内容了怎么办呢?这个时候,我们如何做到既不解压缩,又能获取到解压以后的大小?
如果你本地检查一个.gz文件,那么你可以使用命令gzip -l xxx.gz来查看它的头信息:
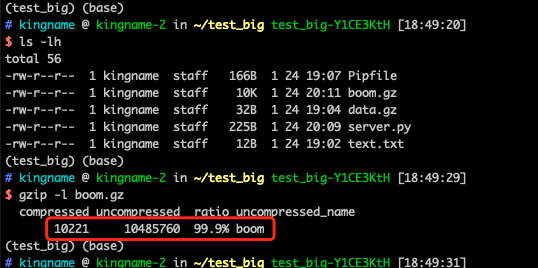
打印出来的数据中,第一个数字是压缩后的大小,第二个数字是解压以后的大小,第三个百分比是压缩率。这些信息是储存在压缩文件的头部信息中的,不用解压就能获取到。
那么当我使用Requests的时候,如何获得压缩后的二进制数据,防止它擅自解压缩?方法其实非常简单:
import requests
resp = requests.get(url, stream=True)
print(resp.raw.read())
运行效果如下图所示:
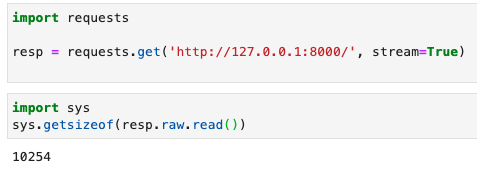
此时可以看到,这个大小是压缩后的二进制数据的大小。现在,我们可以使用如下代码,在不解压的情况下,查询到解压缩后的文件大小:
import gzip
import io
import requests
resp = requests.get(url, stream=True)
decompressed = resp.raw.read()
with gzip.open(io.BytesIO(decompressed), 'rb') as g:
g.seek(0, 2)
origin_size = g.tell()
print(origin_size)
运行效果如下图所示:
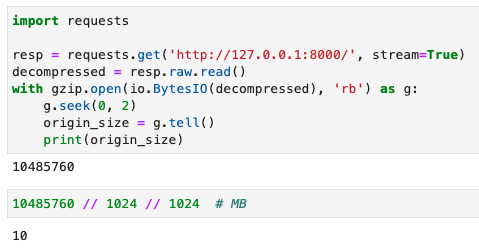
打印出来的数字转成MB就是10MB,也就是我们昨天测试的解压后的文件大小。
使用这个方法,我们就可以在不解压的情况下,知道网站返回的gzip压缩数据的实际大小。如果发现实际尺寸大得离谱,那就可以确定是gzip炸弹了,赶紧把它丢掉。