1. 技术背景
互联网的迅猛发展受益于网络通信技术的成熟和稳定。网络通信协议是机器双方共同约定的协议。在应用层看到的是结构体、对象,但是在网络协议里,机器之间传输的都是二进制流。网络编程中,需要定义应用层协议。最原始的应用层协议是字节数组,在 Java 语言里以 byte[]体现,在C语言里以 char[]体现。不管是 Java 语言还是 C 语言,开发人员都需要知道字节数组里每个字节的含义才能保证数据写入和读取的正确性。这对开发人员来说,是非常严苛且低效的。
如何将程序中的结构体、对象等结构化内存对象转换为扁平的二进制流?如何将二进制流还原为结构化内存对象?为了解决这些问题,序列化/反序列化技术应运而生。

核心意义:对象状态的保存(序列化)和重建(反序列化)
2. 序列化协议的特性
-
通用性
- 技术层面,序列化协议是否支持跨平台、跨语言。如果不支持,在技术层面上的通用性就大大降低了。
- 流行程度,社区是否成熟,是否能及时跟进Issue并解决Bug。
-
鲁棒性
- 成熟度不够,一个协议从制定到实施,到最后成熟往往是一个漫长的阶段。协议的强健性依赖于大量而全面的测试,对于致力于提供高质量服务的系统,采用处于测试阶段的序列化协议会带来很高的风险。
- 语言/平台的不公平性。为了支持跨语言、跨平台的功能,序列化协议的制定者需要做大量的工作;但是,当所支持的语言或者平台之间存在难以调和的特性的时候,协议制定者需要做一个艰难的决定–支持更多人使用的语言/平台,亦或支持更多的语言/平台而放弃某个特性。当协议的制定者决定为某种语言或平台提供更多支持的时候,对于使用者而言,协议的强健性就被牺牲了。
-
可扩展性/兼容性
- 扩展性表现为随着业务需求变化需要增减字段。字段变化的过程中,不会对现有系统的数据存储、数据访问造成影响,具有向后兼容性。扩展性也是序列化/反序列化技术的核心指标之一。
-
性能
- 时间开销,复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化阶段成为整个系统的瓶颈。
- 空间开销,如果序列化过程引入的额外开销过高,可能会导致过大的网络,磁盘等各方面的压力。对于海量分布式存储系统,数据量往往以TB为单位,巨大的的额外空间开销意味着高昂的成本。
-
易用性
- 易用性决定了开发者是不是需要花很多时间去学习,门槛是不是很高,接口是不是容易理解和使用。
-
安全性
- 安全性也是序列化工具选型的重要参考意见,比如广泛使用的fastjson,很多版本都存在RCE漏洞。
3. 序列化引擎
一般来说,序列化/反序列化分为IDL(Interface Description Language,接口描述语言)和非IDL两类。非IDL技术方案包含 JSON、XML等,提供构造和解析的工具包即可使用,不需要做代码生成的工作。IDL技术方案包含 Thrift、Protocol Buffer、Avro 等,有比较完整的规约和框架实现。
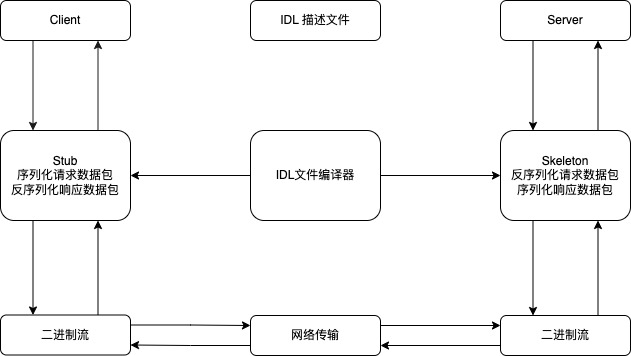
IDL工作原理图
IDL 描述文件:比如,Thrift 是以 thrift 为后缀的文件,Protocol Buffer是以 proto 为后缀的文件。
IDL 文件编译器:根据 IDL 文件生成具有序列化/反序列化功能的代码文件。例如,Thrift 通过 thrift 命令行指定编程语言类型来生成代码文件,Protocol Buffer 根据 protoc 命令行生成代码文件。
Stub/Skeleton 代码:在客户(Client)端,一般称为 Stub 代码。在服务器(Server)端,一般称为 Skeleton 代码。
4. Java序列化方式
4.1 实现Serializable接口
4.1.1 默认的序列化/反序列化
实现 Serializable 接口是最常用的序列化方式,以下是简单示例
- 准备一个待序列化的对象
package com.wick.pojo;
import lombok.*;
import java.io.Serializable;
@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private String name;
private int age;
private String address;
}
- 执行序列化操作
package com.wick;
import com.wick.pojo.User;
import java.io.File;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.nio.file.Files;
public class App
{
public static void main( String[] args ) throws IOException {
User user = new User("wick", 18, "beijing");
try (ObjectOutputStream os = new ObjectOutputStream(Files.newOutputStream(new File("user.out").toPath()))){
os.writeObject(user);
};
}
}
在上面的例子中,我们使用 ObjectOutputStream.writeObject(Object obj ) 方法来完成对象的序列化,并保存到本地文件中,我们可以使用二进制文件编辑器打开看下文件内容
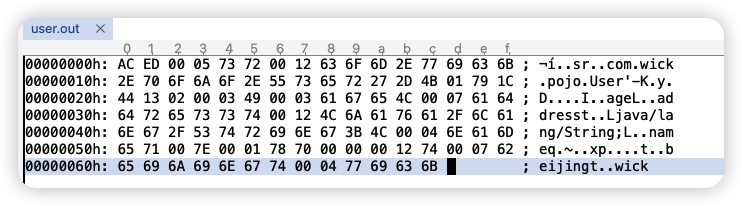
同样的,我们也可以使用 ObjectInputStream.readObject() 方法来将一个对象反序列化出来。
@Test
public void test() throws IOException, ClassNotFoundException {
ObjectInputStream ins = new ObjectInputStream(Files.newInputStream(new File("user.out").toPath()));
User user = (User) ins.readObject();
System.out.println(user);
}
// out: User(name=wick, age=18, address=beijing)
除了使用默认的序列化机制外,对于一些特殊的类, 我们需要定制序列化和反序列化方法的时候,可以通过重写以下方法实现。
private void writeObject(java.io.ObjectOutputStream out) throws IOException;
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
private void readObjectNoData() throws ObjectStreamException;
上面的三个方法,并不是 Serializable 接口中的方法,而是特殊名称的方法,只要实现了 Serializable 接口,就可以通过重写这几个方法来实现定制的序列化和反序列化需求,jdk 中的很多类都有此操作,有兴趣的可以自行查看各自的实现,此处不做展开。
4.1.2 自定义序列化/反序列化
- 对于上面的 User 类,我们可以通过重写
writeObject(java.io.ObjectOutputStream out)方法来实现自定义的序列化,代码如下所示
package com.wick.pojo;
import lombok.*;
import java.io.IOException;
import java.io.Serializable;
@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private String name;
private int age;
private String address;
private void writeObject(java.io.ObjectOutputStream s) throws IOException {
s.defaultWriteObject();
// 追加 toString() 的内容
s.writeBytes("name: " + name + ", age: " + age + ", address: " + address);
}
}
- 序列化对象
@Test
public void testSerializer() throws IOException {
User user = new User("wick", 18, "beijing");
try (ObjectOutputStream os = new ObjectOutputStream(Files.newOutputStream(new File("user1.out").toPath()))){
os.writeObject(user);
};
}
-
使用工具查看生成的二进制文件内容,可以明显看到后面追加了刚才
toString()方法的内容,这样就实现了对象的自定义序列化。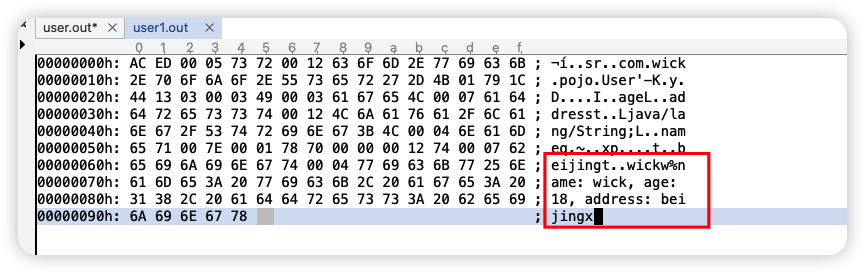
-
同样的,我们也可以通过重写
readObject(java.io.ObjectInputStream s)方法来实现自定义的反序列化操作
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
// 读取 toString() 的内容
byte[] bytes = new byte[1024];
int len = s.read(bytes);
String[] split = new String(bytes, 0, len).split(",");
// 此处,将 name 和 address 属性交换读取,不然看不出来区别
this.address = split[0].split(":")[1].trim();
this.age = Integer.parseInt(split[1].split(":")[1].trim());
this.name = split[2].split(":")[1].trim();
}
- 反序列化对象
@Test
public void test() throws IOException, ClassNotFoundException {
ObjectInputStream ins = new ObjectInputStream(Files.newInputStream(new File("user1.out").toPath()));
User user = (User) ins.readObject();
System.out.println(user.toString());
}
// out: User(name=beijing, age=18, address=wick)
4.2 实现Externalizable接口
除了实现 Serializable 接口完成序列化/反序列化外,还可以通过实现 Externalizable 接口达到序列化/反序列化的目的, 但是如果实现了 Externalizable 接口, 那就必须实现 writeExternal(ObjectOutput out) 和 readExternal(ObjectInput in) 方法。
- 以下我们还是以简单的 Person 类来举例。
package com.wick.pojo;
import lombok.*;
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
/**
* @author: wick
* @date: 2023/5/3 12:09
* @description:
*/
@Setter
@Getter
@NoArgsConstructor // 必须要有无参构造,如果没有重写构造方法,则默认会有无参构造
@ToString
@AllArgsConstructor
public class Person implements Externalizable {
private String name;
private int age;
private String address;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeInt(age);
out.writeObject(address);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
age = in.readInt();
address = (String) in.readObject();
}
}
- 序列化对象
@Test
public void test2() throws IOException {
Person person = new Person("wick", 18, "nanjing");
try (ObjectOutputStream os = new ObjectOutputStream(Files.newOutputStream(new File("person.out").toPath()))){
os.writeObject(person);
};
}
- 使用工具查看序列化后的内容
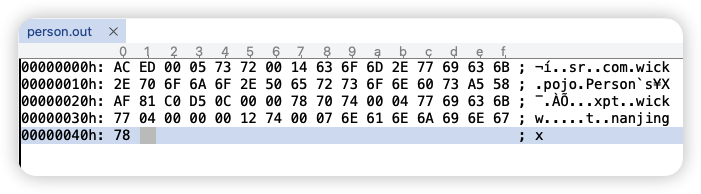
- 反序列化对象
@Test
public void test3() throws IOException, ClassNotFoundException {
ObjectInputStream ins = new ObjectInputStream(Files.newInputStream(new File("person.out").toPath()));
Person user = (Person) ins.readObject();
System.out.println(user.toString());
}
// out: Person(name=wick, age=18, address=nanjing)
4.3 两种序列化方式的比较
-
实现方式
-
Serializable 接口:是 Java 语言提供的标记接口,即不需要实现任何方法,只需要在类名加上
implements Serializable即可。当一个对象被序列化时,Java 的序列化机制会把对象的状态保存到一个字节序列中。而当一个对象被反序列化时,Java 的序列化机制会根据保存的字节序列来创建并初始化一个对象。 -
Externalizable 接口:需要实现
readExternal和writeExternal两个方法,用来表示如何序列化和反序列化一个对象。可以通过这两个方法来控制对象状态的写入和读取。readExternal和writeExternal方法不是由 Java 序列化机制调用的,而是需要手动调用,因此可以进行一些额外的初始化或特殊操作。
-
-
序列化效率
-
Serializable 接口:在序列化和反序列化一个对象时,序列化机制会自动地对该对象的所有非静态成员进行序列化和反序列化操作。因为使用的是自动序列化机制,这可能会创建一些不必要的对象和字节数组,从而降低序列化的效率,尤其当某个类的父类也实现了可序列化接口时,更耗费资源。
-
Externalizable 接口:由于对对象的序列化和反序列化过程都是手动控制的,
Externalizable实现的序列化效率比Serializable高,特别是在序列化大型对象图时。但是,需要手动调用接口的方法,可能需要更多的代码开销和维护成本。
-
综上所述,Serializable 接口更加简单且容易实现,但是效率相比于 Externalizable 接口会下降;而 Externalizable 接口需要手动编写序列化和反序列化的方法,但是它提供了更好的控制序列化的过程并且具有更高的序列化效率。
5 Java序列化核心类/接口
5.1 Serializable
Serializable 接口源码如下:
public interface Serializable {
}
Serializable 是一个空接口,表明了实现自该接口的子类具有序列化行为特征,所有要支持序列化的类都应该实现这个接口。在后面介绍 ObjectOutputStream 的writeObject 方法时,会解释为什么必须这么做。
5.2 Externalizable
Externalizable 接口源码如下:
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
此接口有两个必须要重写的方法,在上面我们已经介绍过,writeExternal 的参数是 ObjectOutput,表示输出对象的抽象,它继承自 DataOutput,能支持基本类型、String、数组、对象的输出。实际应用中,会使用它的实现类 ObjectOutputStream。 readExternal 的参数是 ObjectInput,表示输入对象的抽象,它继承自 DataInput,能支持基本类型、String、数组、对象的输入。实际应用中,会使用它的实现类 ObjectInputStream。自定义的类必须包含无参构造函数。
5.3 ObjectOutputStream
java.io.ObjectOutputStream 是实现序列化的关键类,它可以将一个对象转换成二进制流,然后通过 ObjectInputStream 将二进制流还原成对象。为了能更好地理解 ObjectOutputStream,先简要说明其内部的几个关键类:
5.3.1 BlockDataOutputStream
BlockDataOutputStream 是Java标准库中的一个类,它是DataOutputStream 的子类,用于提供对数据进行块写入的功能。BlockDataOutputStream 类主要用于为ObjectOutputStream 类提供支持。在对象序列化过程中,ObjectOutputStream 会使用 BlockDataOutputStream 来处理原始数据的写入。
以下是BlockDataOutputStream的一些主要特点和功能:
-
块数据写入:
BlockDataOutputStream允许以块的形式,将原始数据按照一组字节进行写入。块数据包含了一些元信息,如块长度、类型等,以便在反序列化时进行正确的解析。 -
压缩:
BlockDataOutputStream可以对数据进行压缩,以减小序列化数据的大小,提高传输效率。 -
写入类型:除了基本的数据类型,
BlockDataOutputStream还支持写入字符串、数组、特定类型对象等。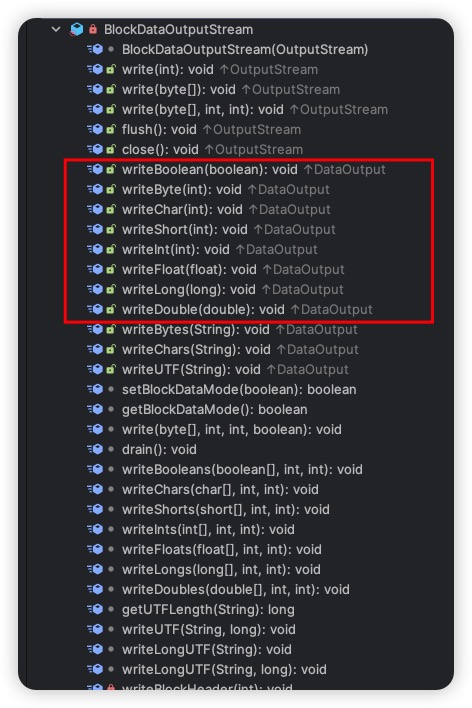
-
缓冲区管理:
BlockDataOutputStream使用内部缓冲区(Buffer)来提高写操作的性能。缓冲区会在需要时被填满并进行刷出。
简单来说,BlockDataOutputStream是用于支持对象序列化过程中的底层数据写入。它提供了块数据写入的功能,可以进行压缩以减小数据大小,同时也实现了缓冲区管理,以提高写入操作的性能。作为 ObjectOutputStream 内置的具有缓冲作用的输出功能类,包含阻塞和非阻塞两种工作模式。两种模式的工作流程相同,都是先把待写的数据写到缓冲区,直到缓冲区满后再执行真正的写入操作,只是在阻塞模式下,每次将缓冲区数据写入之前会写入一个阻塞标记头部(Block Data Header)。
5.3.2 HandleTable
管理对象引用的处理,在 Java 的序列化机制中,如果一个对象被多次引用,那么在序列化过程中会将对象序列化为多个拷贝,这样会导致序列化结果变得冗长。为了解决这个问题,Java 序列化机制使用了对象引用句柄。HandleTable 类的作用是维护了一张对象引用句柄表,用来管理对象的序列化和反序列化过程中的引用处理。它通过使用句柄来代替重复的对象,从而实现对象的共享和压缩。具体来说,HandleTable 类中的 handles 数组存储了对象的引用句柄,索引值作为句柄值。当序列化一个对象时,ObjectOutputStream 会将对象写入输出流,并将其句柄(索引值)写入句柄表中。当序列化过程中遇到同一个对象的引用时,它会使用相同的句柄值来表示该对象,这样就实现了对象的共享。在反序列化过程中,ObjectInputStream会根据句柄值从句柄表中获取对应的对象引用。通过使用句柄表,HandleTable 类可以有效地减少序列化结果的大小,并提高序列化和反序列化的效率。它是Java序列化机制中的一个关键组件,帮助实现了序列化对象的共享和压缩。我们可以通过下面一张图来理解这个过程。
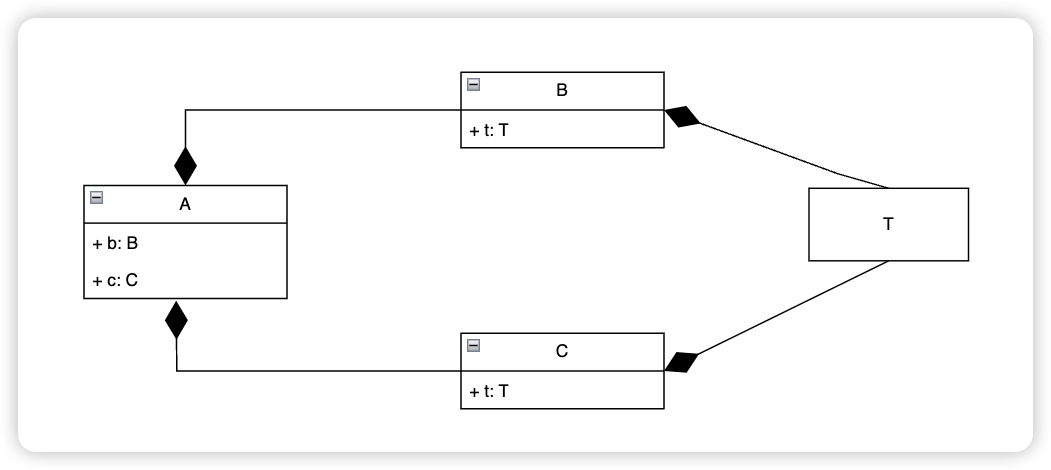
在上面这张简单的表示组合关系的类图中,我们可以看到 A 类是由 B 和 C 两个类来组合得到的,而 B,C 类内部都有 T 类,如果没有 HandleTable,那 A类的序列化过程就会变成:
- 构造对象 B 和 C
- 在 B 中构造对象 T,在 C 中构造对象 T
从上面这个过程我们发现,T 这个对象会分别在 B 和 C 中被构造一次,如果是更为复杂的对象,那么对于 T 来说,可能会出现非常多的拷贝对象,但是当引入 HandleTable 之后,事情就变得简单了,比先构造对象 B,然后发现用到了 T,则构造一次,并使用一个 Object[] 来缓存这个 T 对象,当构造 C 的时候发现它也用到了对象 T,则直接会从 Object[] 中取到这个对象的引用,避免了二次创建对象,下面是HandleTable类的简化示例:
class HandlesTable {
private Object[] handles; // 引用句柄表
public void setObject(int handle, Object obj) {
// 设置句柄对应的对象引用
handles[handle] = obj;
}
public Object getObject(int handle) {
// 获取句柄对应的对象引用
return handles[handle];
}
}
通过使用数组作为存储结构,HandleTable 能够快速通过句柄值来获取对应的对象引用。通过索引操作,可以直接访问数组的元素,无需进行遍历或搜索操作,因此具有较快的存取速度。当需要序列化和反序列化对象时,HandleTable 会根据需要动态扩展数组的大小,以适应不同数量的对象引用。
5.3.3 ReplaceTable
ReplaceTable类的主要作用是在序列化过程中,当遇到可以被替换的对象时,将对象替换为其他对象。这样可以更好地控制序列化的结果,实现自定义的序列化逻辑。具体来说,ReplaceTable类维护了一个替换表(Replacement table),它是一个Map数据结构,用于存储对象的替代对应关系。在序列化过程中,当要序列化一个对象时,ObjectOutputStream会检查该对象是否实现了writeReplace()方法。若实现了此方法,ObjectOutputStream会调用该方法获取替代对象,并将替代对象进行序列化。如果替代对象不为null,则将替代对象添加到替换表中。在后续的序列化过程中,如果遇到与替换表中的对象相等的对象时,ObjectOutputStream会将该对象替换为替代对象进行序列化。这样可以在序列化过程中实现对象替换,更好地控制序列化结果。通过使用ReplaceTable类,可以在序列化过程中灵活地替换对象,实现自定义的序列化行为,例如实现对象的版本控制、对象的压缩、对象的安全性检查等。
5.3.4 ObjectStreamClass
ObjectStreamClass 的主要作用是提供关于类的序列化和反序列化的元数据信息。它存储了与类相关的信息,并在序列化和反序列化时使用这些信息来进行匹配和操作。通过 ObjectStreamClass ,我们可以了解类的版本号、类的字段信息以及类的序列化支持情况等。这使得在进行序列化和反序列化过程时,能够正确地处理对象的属性和版本兼容性。以下是其核心字段及作用:
| 字段 | 字段意义 |
|---|---|
| Class<?> cl | 序列化类的 Class 类型 |
| String name | 序列化类的完整类名 |
| volatile Long suid | 序列化 ID,使用 volatile 关键字还可以禁止编译器进行某些优化,例如重排序。这是因为在对象序列化和反序列化的过程中,与版本号相关的操作必须按照特定的顺序进行,否则可能导致不正确的结果。 |
| boolean isProxy | 是否是代理类 |
| boolean isEnum | 是否是枚举类 |
| boolean serializable | 是否实现了 Serializable 接口 |
| boolean externalizable | 是否实现了 Externalizable 接口 |
| boolean hasWriteObjectData | 是否使用自定义的 writeObject 方法写数据 |
| boolean hasBlockExternalData | 类是否包含阻塞式外部数据,阻塞式外部数据指的是在进行对象的序列化时,如果存在某些在序列化过程中需要阻塞的外部数据(比如通过网络传输),那么阻塞式外部数据就会设置为true。 当hasBlockExternalData字段为true时,序列化和反序列化过程中的某些步骤可能会被阻塞,直到外部数据就绪或可用。这样可以确保在序列化和反序列化过程中正确地处理外部依赖。通过这个字段,ObjectStreamClass类在序列化和反序列化时可以根据需要采取相应的行动,以确保阻塞式外部数据正常处理。 |
| ClassNotFoundException resolveEx | 尝试解析类时发生的异常 |
| ExceptionInfo deserializeEx | 非枚举类反序列化异常,ExceptionInfo 也是 ObjectStreamClass 的一个内部类,表示操作类时产生的异常 |
| ExceptionInfo serializeEx | 非枚举类序列化异常 |
| ExceptionInfo defaultSerializeEx | 尝试默认序列化时引发的异常 |
| ObjectStreamField[] fields | 可序列化字段 |
| int primDataSize | 基本类型的成员字段个数,不包含被 static 和 transient 修饰的字段 |
| int numObjFields | 非基本类型的成员字段个数 |
| FieldReflector fieldRefl | 缓存与类相关联的字段反射信息。它提供了一个快速访问字段的能力,避免了每次进行字段反射访问时的性能开销 |
| volatile ClassDataSlot[] dataLayout | 类的层次结构:当前类,父类,及其所有子类的类描述 |
| Constructor<?> cons | 适合序列化的构造函数,如果没有,则为 null |
| ProtectionDomain[] domains | 与类相关联的保护域(ProtectionDomain)的数组。这些保护域定义了在序列化和反序列化过程中对类的访问权限。ProtectionDomain是Java安全性机制中的一个概念,它代表了一组相关代码的安全域。每个ProtectionDomain都由一个代码源(code source)和一组权限(permissions)组成。当一个对象被序列化时,其类信息会被存储在序列化数据中。在反序列化过程中,为了确保安全性,Java虚拟机(JVM)必须验证反序列化的类是否具有足够的权限进行访问。这个验证过程使用了类的保护域信息。通过domains属性,ObjectStreamClass可以存储和获取与类相关联的保护域信息。这些保护域将在反序列化过程中被用于验证类的访问权限。 |
| Method writeObjectMethod | 序列化方法,通过反射获取 |
| Method readObjectMethod | 反序列化方法,通过反射获取 |
| Method writeReplaceMethod | 当一个对象被序列化时,如果该对象类中定义了writeReplace()方法,那么在序列化过程中将调用这个方法来确定要序列化的对象。writeReplace()方法负责返回实际要序列化的对象。这样可以灵活地控制对象的序列化过程。 |
| Method readObjectNoDataMethod | 如果该对象类中定义了readObjectNoData()方法,那么在反序列化过程中将调用这个方法进行对象的初始化。readObjectNoData()方法用于在反序列化之后对反序列化得到的对象进行进一步处理,以确保对象的完整性和一致性 |
| Method readResolveMethod | 当一个对象被反序列化时,如果该对象类中定义了readResolve()方法,那么在反序列化过程中将调用这个方法来确定实际要返回的对象。readResolve()方法负责返回一个替代的对象,以确保在反序列化后得到的对象与原始对象保持一致。 |
| ObjectStreamClass localDesc | 当前类描述 |
| ObjectStreamClass superDesc | 父类描述 |
| boolean initialized | 对象是否已经初始化完成 |
5.4 ObjectInputStream
java.io.ObjectInputStream 是实现Java反序列化的关键类,和 ObjectOutputStream 是对应的,内部包含了 BlockDataInputStream、HandleTable、ReplaceTable、ObjectStreamClass 等,这里不展开描述。
6. Java 序列化原理
以上,我们了解到了 java 实现序列化的方式,以及序列化过程中会用到的核心类/接口,接下来我们需要知道Java序列化的流程、原理,以及各种类型数据进行Java序列化后的格式和占用空间大小等细节,这也是序列化技术的核心所在。不同序列化方案的技术细节不尽相同,对各种数据类型处理后的格式和大小也不尽相同。
6.1 基本类型数据序列化流程
在学习基本类型的序列化流程之前,我们先回顾两个知识点
- Java 中基本数据类型有几种,及其长度
| 数据类型 | 字节长度 |
|---|---|
| int | 4字节(-2,147,483,648 到 2,147,483,647) |
| long | 8字节(-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807) |
| double | 8字节(IEEE 754双精度浮点数) |
| char | 2字节(无符号Unicode字符,以UTF-16编码表示,可存储一个unicode字符) |
| byte | 1字节(-128 到 127) |
| boolean | 1 位,只能是 true 或者 false |
| short | 2字节(-32,768 到 32,767) |
| float | 4字节(IEEE 754单精度浮点数) |
- 字节的高低位
在计算机中,一个字节由8个位(bit)组成。在一个字节中的每个位都有特定的位置。位可以被编号,从最右边的位(称为最低有效位)开始,往左依次递增编号,最左边的位称为最高有效位,也称为高位。其实这个很好理解,在电视上我们也见过支票,支票的金额就是从左往右写的

比如上面这张图,在右边的金额栏,从左往右依次是高单位到低单位,所以最左边的就是高位,最右边的就是低位。
字节的高位和低位术语通常用于表示多字节数据类型(如整数)的个别字节在内存中的存储顺序。在多字节的数据类型中,数据在内存中以连续的字节序列存储,而字节序列的顺序可以是"大端"或"小端"。
- 大端字节序:最高有效位存储在起始地址,最低有效位存储在最后地址。
- 小端字节序:最低有效位存储在起始地址,最高有效位存储在最后地址。
举个例子,假设一个整数值0x12345678在内存中按照大端字节序存储。将这个整数值转换为字节序列时,高位字节0x12存储在起始地址,低位字节0x78存储在最后地址。
地址: 0 1 2 3
| 0x12 | 0x34 | 0x56 | 0x78 |
相反,如果按照小端字节序存储,高位字节0x78存储在起始地址,低位字节0x12存储在最后地址。
地址: 0 1 2 3
| 0x78 | 0x56 | 0x34 | 0x12 |
在Java中,默认使用的是采用大端字节序(Big Endian)的内存存储模式。这意味着在多字节数据类型(如int、long、float、double等)存储在内存中时,最高有效字节存储在起始地址,按顺序向后存储。
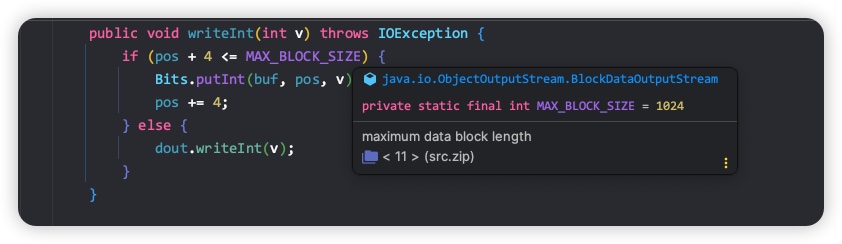
回顾完上面两个问题,我们继续看 Java 是如何序列化基本类型数据的,Java序列化对基本类型数据的处理,严格按照其内存占用大小来进行。比如int类型占用4字节,Java 序列化按照高位到低位依次放到字节数组,再写入到序列化输出对象,真正的写入是通过调用 BlockDataOutputStream 的 writeInt 方法实现的。BlockDataOutputStream 内部维护了一个1024字节大小的缓冲区,如果缓冲区还可以容纳待写入的 int 类型数据,则把当前数据放入缓冲区;如果缓冲区不能容纳待写入的int类型数据,则调用 DataOutputStream 的 writeInt 方法,如以下代码所示:
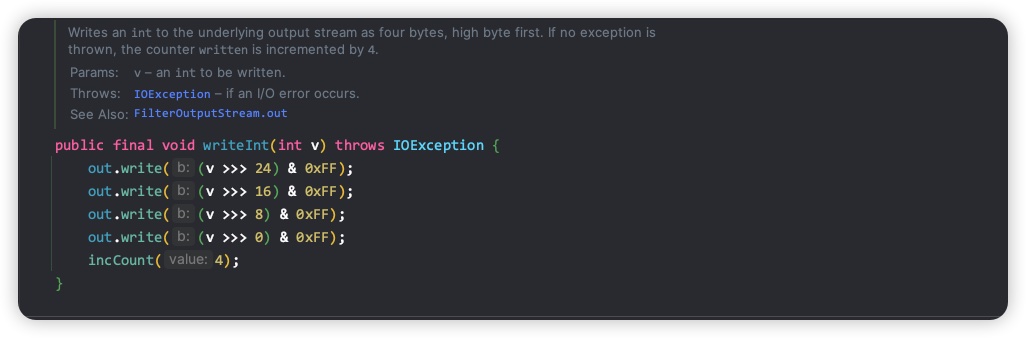
接下来我们看下 DataOutputStream 的 writeInt() 方法是如何写 int 类型数据的
我们可以逐步看下这几段代码的含义:
- out.write(): 很明显这是一个写入操作,可以将内容写入文件或者套接字。
- v >>> 24: 这是一个无符号右移操作符,将v向右移动24位(int 长度 4 字节,即 32 位,从第一个字节(8位)开始向右移动24 位即可达到最低位 32 )。右移操作是将二进制表示中的各位数值向右移动指定的位数,右边的空位用零填充。无符号右移运算符保证移位后左边空出的位总是用零填充。在这个表达式中,我们将整数v的最高8位移动到最低8位,并将其余位数清零,这样就可以提取一个 int 类型变量的最高有效字节的值,而不考虑符号位。
- & 0xFF: 这是一个按位与操作符,将上一步的结果与0xFF(十进制为255)进行按位与操作。0xFF的二进制表示为 00000000 00000000 00000000 11111111。这个操作可以确保结果只保留v最高的8位,将其他位数清零。
从上面的代码我们可以看出,确实是按照从高到低的顺序来写入的。我们继续看 out.write() 做了什么(在当前流程中,out 是 BlockDataOutputStream 实例)

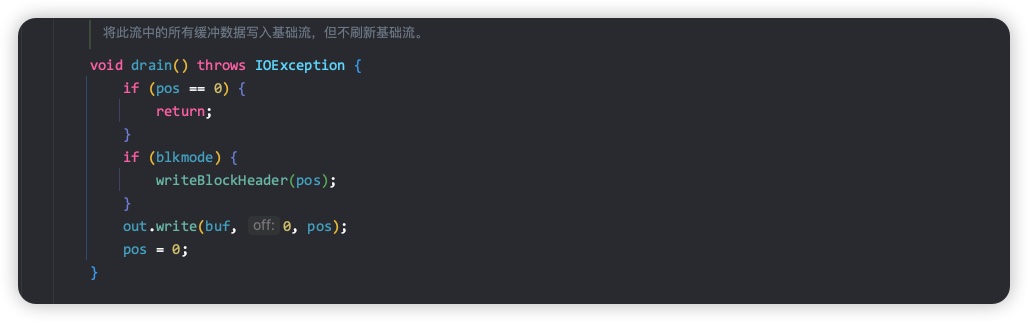
如果缓冲区能容纳当前待写入字节,则把当前字节写入缓冲区;如果缓冲区已满,则会先执行 drain 方法把缓冲区的数据输出,再把当前待写入字节放到缓冲区。通过上述流程,一个 int 类型的数据就写完了,其他类型数据流程类似,此处不做展开。
6.2 对象类型数据序列化流程
学习完基本类型的序列化流程,我们来看下对象类型的数据是怎么被序列化的。Java序列化对非基本类型的数据处理比基本类型的数据处理更复杂,这里说的非基本类型包括Object、Enum、Array等。Java序列化对非基本类型数据的序列化操作是通过 ObjectOutputStream 的 writeObject 方法实现的,接下来将介绍其内部工作原理。
我们先看下 writeObjet 方法定义
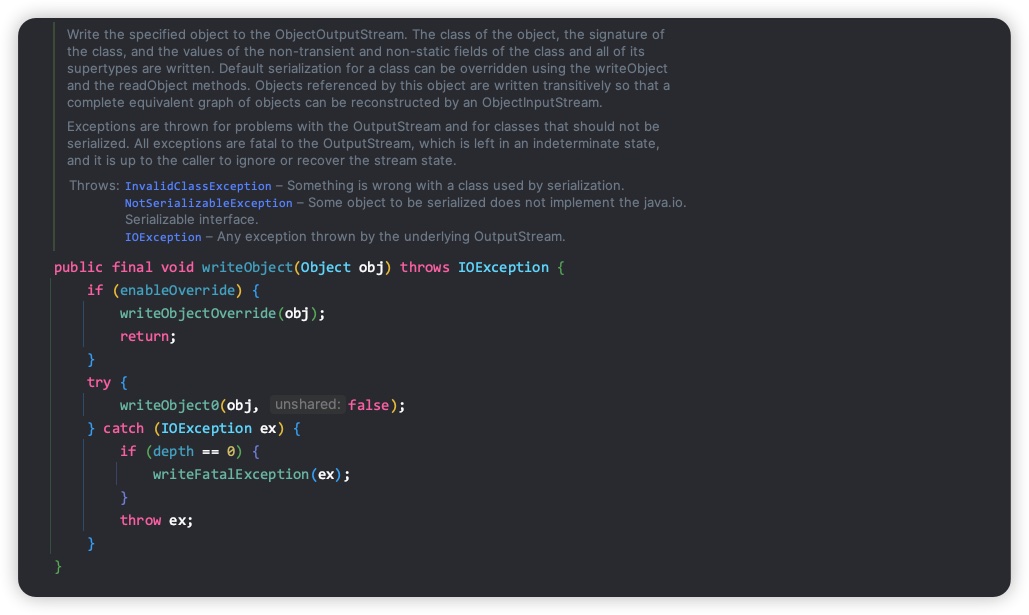
首先检查是否启用了对象写入的重写功能。如果启用了,将调用writeObjectOverride方法,并立即返回。这个条件语句允许自定义的子类重写写入对象的逻辑。obj表示自定义的序列化对象或者Array、Enum类型对象。writeObject0 方法的第2个参数表示一个对象被多个对象共同引用时,在序列化的时候是否要共享写入。如果共享写入,被引用的对象实例只会被序列化一次,其他引用只会写入引用对象句柄。如果不共享写入,被引用的对象实例则会被序列化多次,序列化后的数据大小会增加。在 writeObject 方法里调用 writeObject0,第2个参数默认是false,表示共享写入。
我们继续看下 writeObject0 里面是如何处理非基本类型数据的。
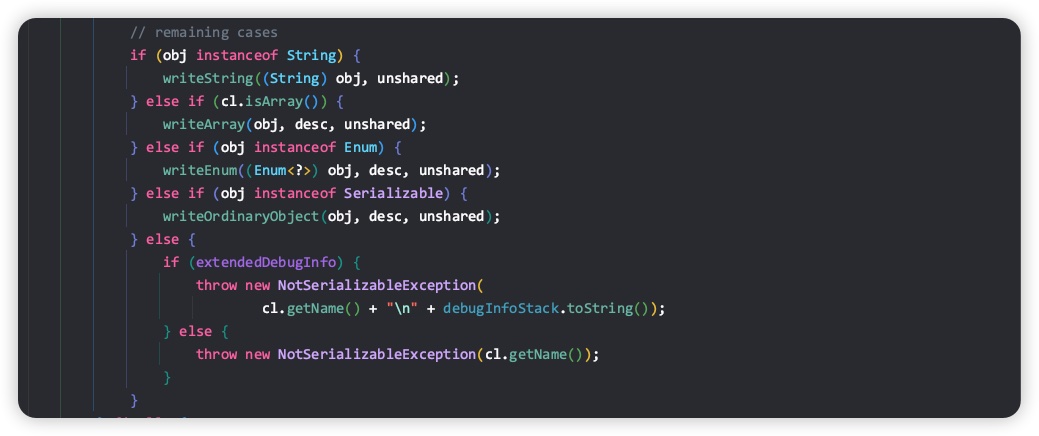
代码比较简单,就是判断 obj 的类型,然后分别调用对应的处理方法,其实如果大家有翻过 String 或者 Enum 的源码,就会发现,这两个类也是实现了 Serializable 接口的,表示这些类都能被正常的序列化。对于Array对象,如果Array的元素是基本类型,则调用基本类型的序列化方式;如果Array的元素是Object类型,则递归调用writeObject0方法来执行序列化,又会执行到上述if分支判断。 如果是自定义的序列化类,则必须实现自Serializable。
总之,要能够被 ObjectOutputStream 的 writeObject 方法序列化,对象必须实现自Serializable,否则会抛NotSerializableException异常。 如果是自定义的序列化类,则会执行 writeOrdinaryObject 方法。
我们看下 writeOrdinaryObject 这个方法是如何处理我们自定义的序列化类的。
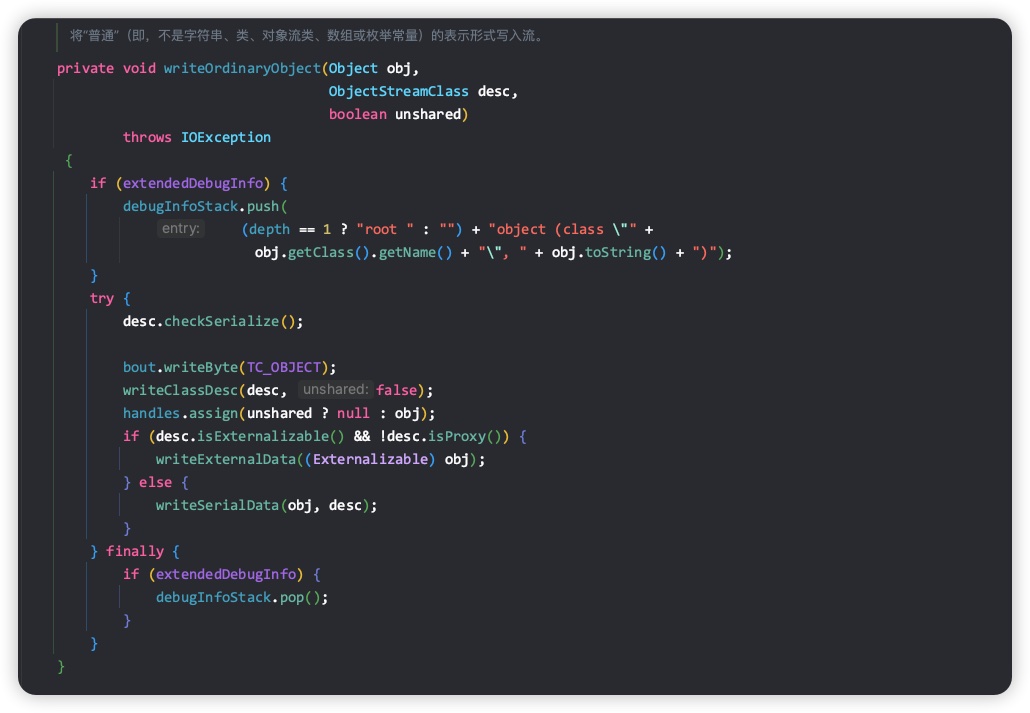
如果自定义的类是 Externalizable 类型并且不是代理类,则调用writeExternalData方法;否则调用writeSerialData方法。Exernalizable继承自Serializable,并增加了writeExternal和readExternal两个接口。我们继续跟进 writeSerialData方法。
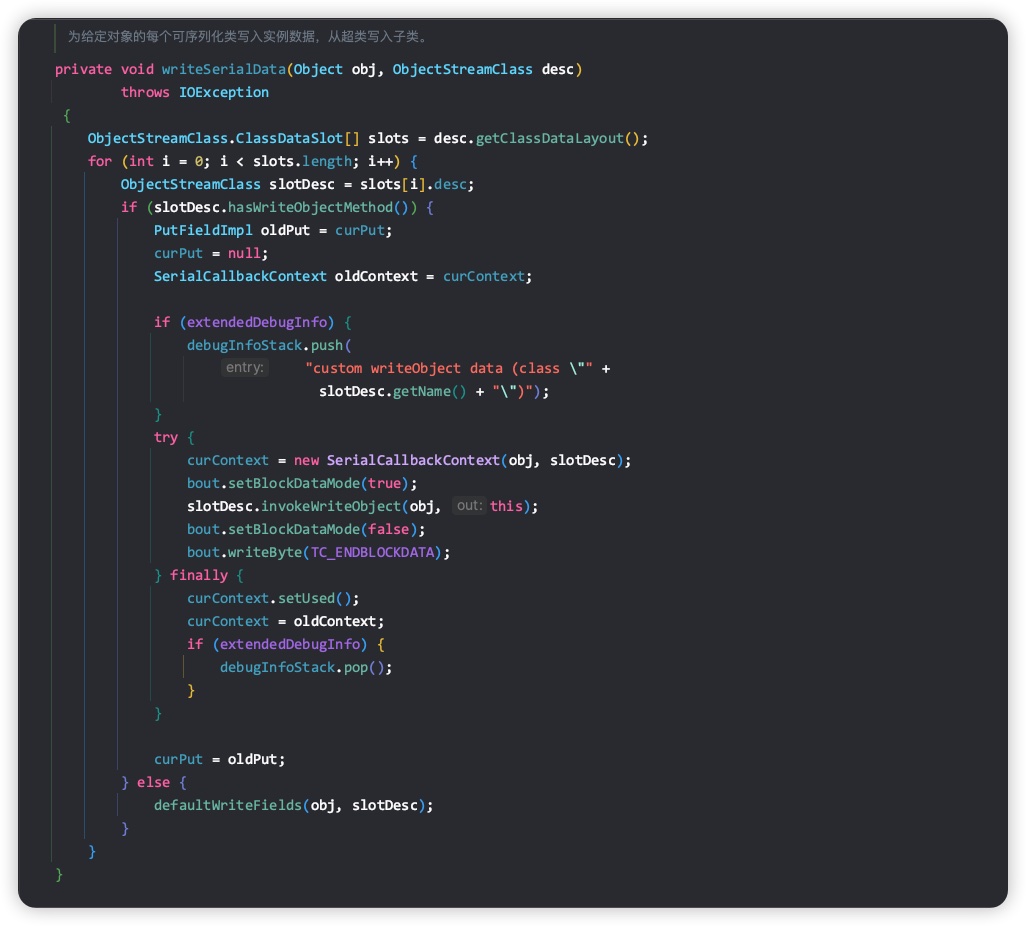
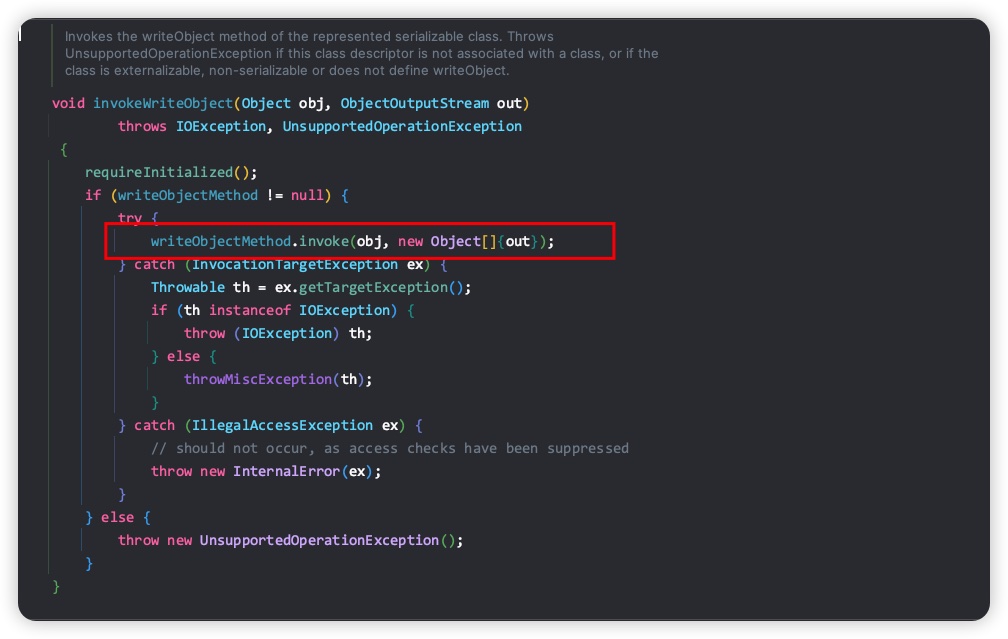
首先获取 obj 对象的布局信息,getClassDataLayout() 表示获取当前类及继承链路上所有直接或间接实现了Serializable的祖先类对应的序列化元数据信息,返回值为ClassDataSlot类型数组,数组元素的顺序是从最根部的祖先类到当前类。ClassDataSlot包含了一个ObjectStreamClass类型的desc字段和boolean类型的hasData字段。ObjectStreamClass类前面已经提过,hasData字段表示desc对应的Java对象是否有数据被序列化。对于ClassDataSlot数组的每一个元素,如果该元素对应的类包含writeObject方法,则调用writeObjet方法。通过查看ObjectStreamClass里的invokeWriteObject方法内部实现,可以看出wirteObject方法以反射方式被调用,代码如下所示。
回到writeSerialData方法内部实现,如果当前待序列化的类没有writeObject方法,则调用defaultWriteFields方法实现序列化,其内部实现如以下代码所示。
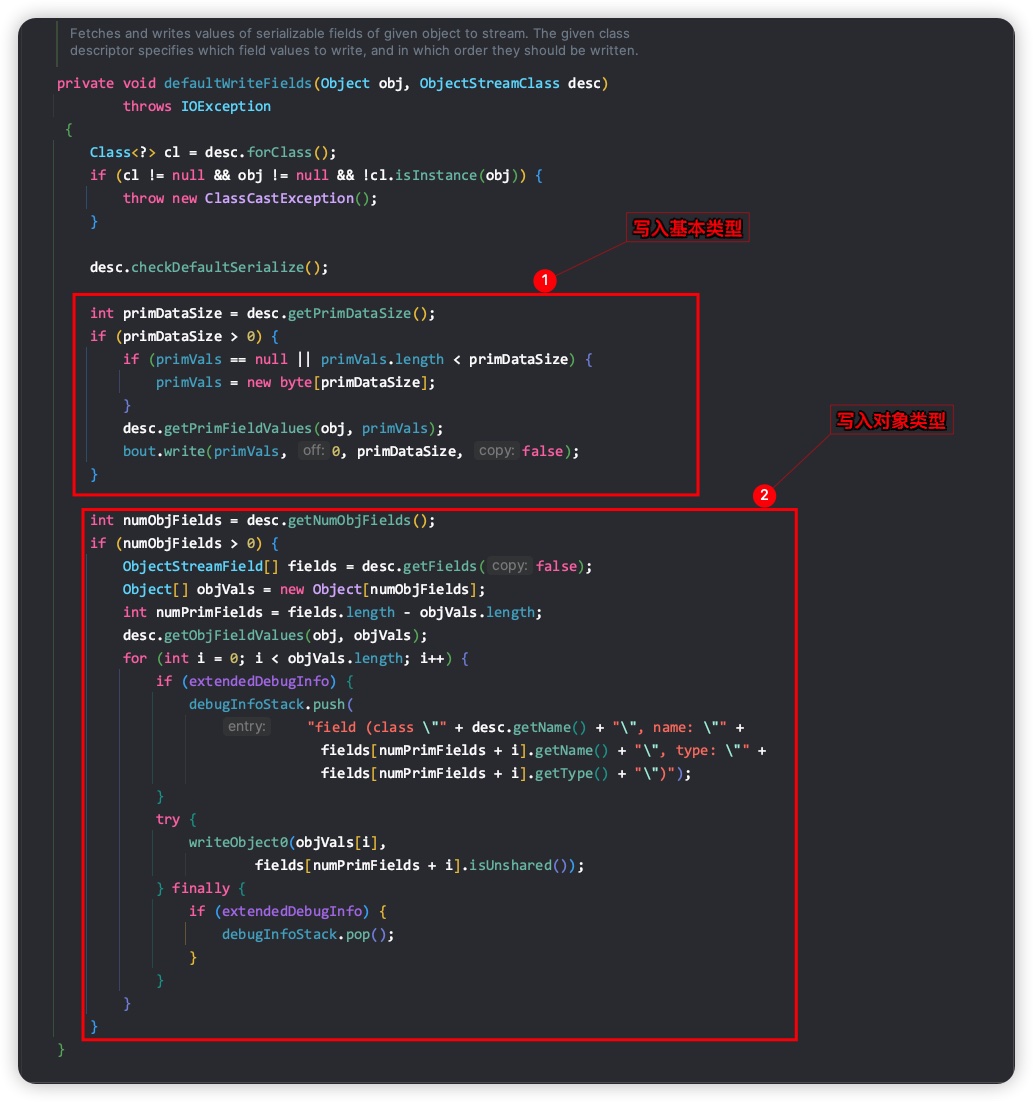
流程也比较简单,就是分开处理基本类型和对象类型的数据,其实没有 writeObject() 方法的类,但是还需要序列化的,我们很明显就知道是实现了 Serializable 接口的类,这也就是为什么你实现了这个序列化接口,但是无需实现序列化方法的原因。
回到writeOrdinaryObject方法实现,如果自定义类实现了Externalizable且不是动态代理类,则会调用writeExternalData方法实现序列化,核心代码如下所示。
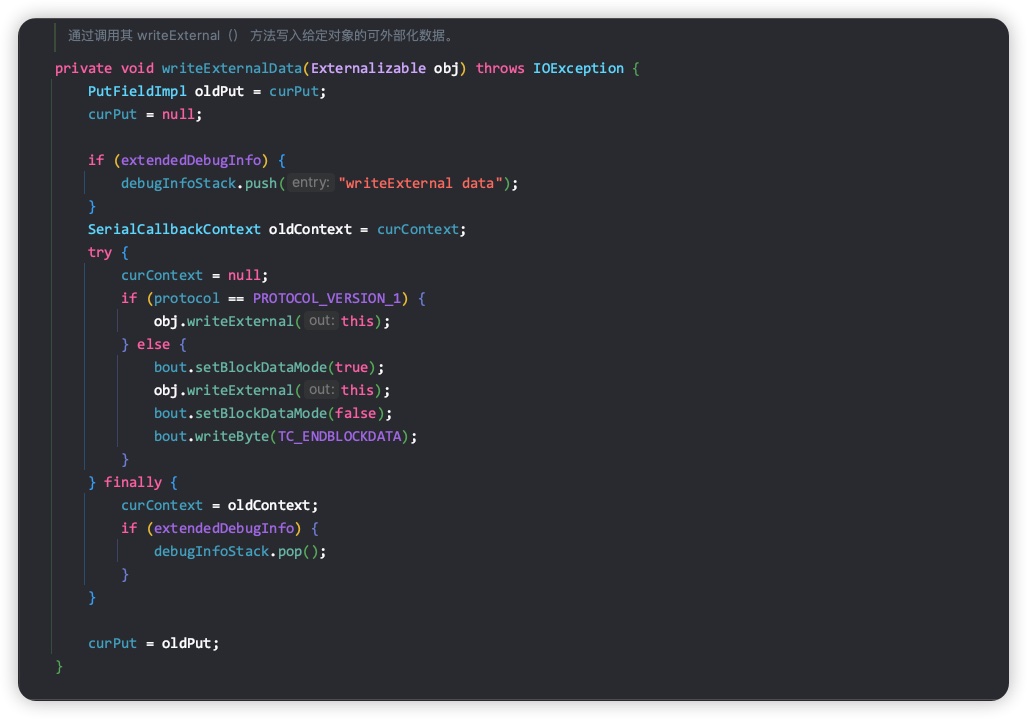
代码最终调用自定义类对象的writeExternal方法实现写入,看起来比Serializable类更简洁,原因是Externalizable接口中包含了readExternal和writeExternal方法,实现了Externalizable的子类必须覆盖readExternal和writeExternal方法。
7. Java 序列化高级特性
7.1 transient 关键字
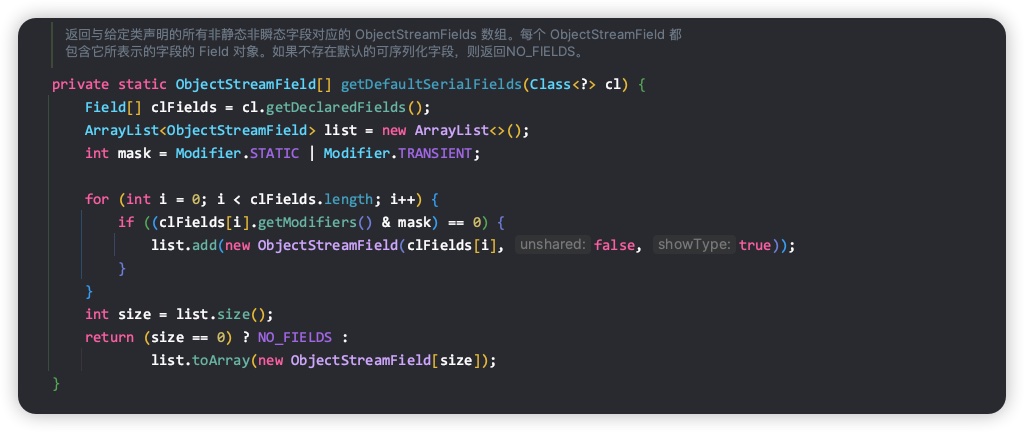
Java序列化可以通过transient关键字来控制字段不被序列化。通过跟进ObjectStreamClass的getDefaultSerialFields方法内部实现,可以看到序列化字段不能为static 且不能为 transient,如以下代码所示:
7.2 static 关键字
static字段属于类全局共有,不会被序列化。在反序列化得到的结果里,静态变量的值依赖类对该静态字段的初始化操作以及是否在同一个JVM进程内。比如说静态变量初始值为0,在序列化之前静态变量的值被设置为10,在同一个JVM进程内执行反序列化操作,得到的静态变量的值为10。如果在另外一个JVM进程内执行反序列化操作,得到的静态变量的值为0。这是因为类在JVM进程内只会被加载一次,相同的类在不同的JVM内都会初始化一遍。
7.3 serialVersionUID
serialVersionUID用来实现类版本兼容,在实际开发中能满足类字段变化的需求。如果我们有一个 Person 类,实现了 Serializable 接口,但是没有定义serialVersionUID字段,对Person类增加一个double类型的字段height,再读取增加字段之前的序列化数据,反序列化会报InvalidCastException 异常。如果Person类定义了serialVersionUID字段,对Person类增加一个double类型的字段height,再读取增加字段之前的序列化数据,反序列化可以成功。
serialVersionUID字段必须是 static+final 类型,否则serialVersionUID字段不会被序列化,通过 ObjectStreamClass 的 getDeclaredSUID 方法实现可以得到验证:
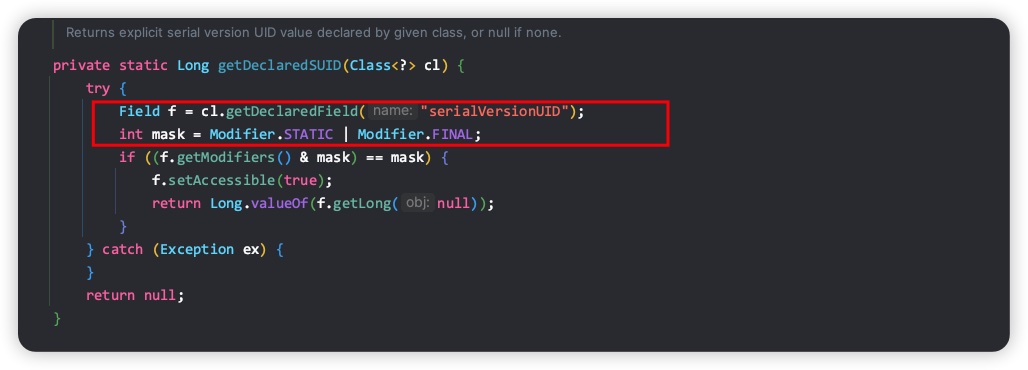
如果不定义serialVersionUID字段,Java序列化会根据类字段和其他上下文计算一个默认值。所以,当类字段发生变化时,serialVersionUID值也会跟着变化,就会出现上述因类字段变化导致反序列化失败的问题。在Java编码规范中,应该强制自定义的序列化类包含serialVersionUID字段,各个Java IDE开发工具均能配置针对serialVersionUID的检查告警级别。
7.4 序列化/反序列化hook
7.4.1 writeReplace 方法
writeReplace方法用于序列化写入时拦截并替换成一个自定义的对象。这个方法也是在 ObjectStreamClass 类中被反射获取的
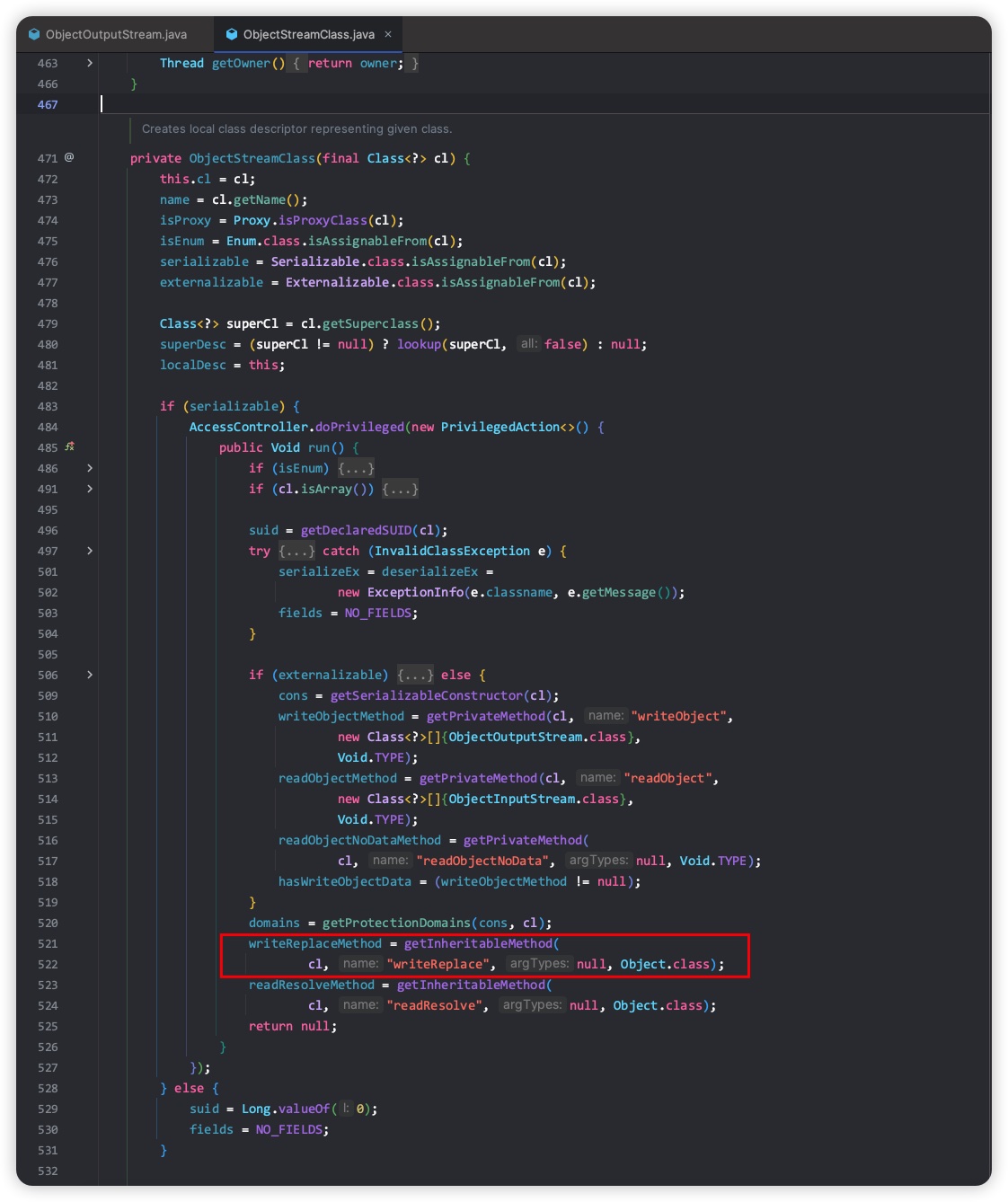
由于writeReplace方法调用是基于反射来执行的,所以作用域限定符不受限制,可以是private、default、protected、public中的任意一种。 如果定义了wirteReplace方法,就没必要再定义writeObject方法了。即使定义了writeObject方法,该方法也不会被调用,内部会先调用writeReplace方法将当前序列化对象替换成自定义目标对象。同理,也没必要定义readObject方法,即使定义了也不会被调用。writeReplace方法的生效原理见ObjectOutputStream的writeObject0方法实现,核心代码如下所示。
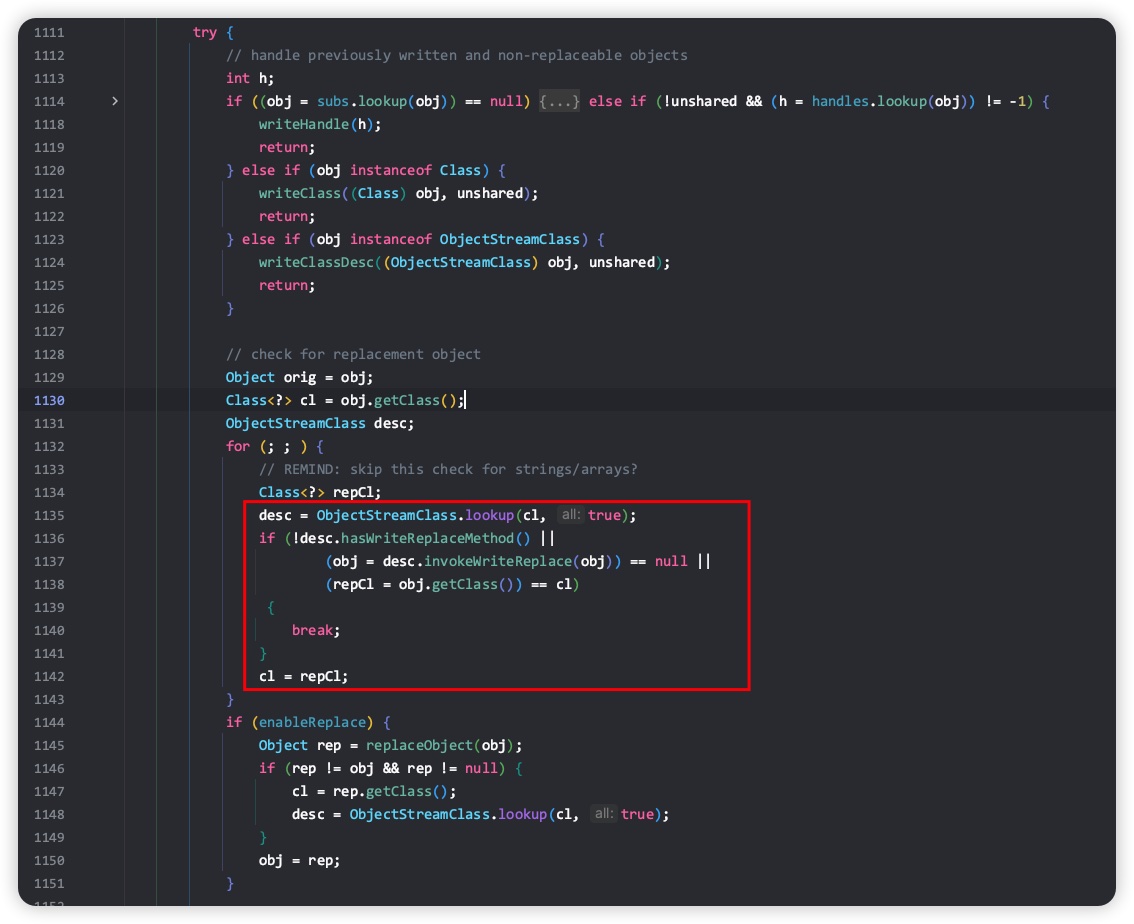
7.4.2 readReplace 方法
readResolve方法用于反序列化拦截并替换成自定义的对象。但和writeReplace方法不同的是,如果定义了readResolve方法,readObject方法是允许出现的。同样的,readResolve 方法也是在 ObjectStreamClass 类中被反射获取的。
readResolve方法的工作原理为:
- 首先调用readObject0方法得到反序列化结果。
- 如果readResolve方法存在,则会调用该方法返回自定义的对象。
- 将自定义的对象作为ObjectInputStream的readObject的返回值。
readResolve方法用在什么场景呢?常见的一种场景是类实现的枚举类型,枚举对象在反序列化时做恢复性保护。对于类实现的枚举类型,反序列化出来的枚举对象期望是定义的枚举对象,这也体现了枚举的意义。但是从代码执行情况看,反序列化出来的的枚举对象是一个新建出来的枚举对象,虽然值和枚举值定义的一样,但不是同一个对象。因此,需要在反序列化的过程中对枚举对象进行恢复保护,readResolve方法就派上用场了。示例如下:
未使用 readResolve 方法前:
package com.oppo.serializedemo.pojo.po;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import java.io.*;
/**
* @author: wick
* @date: 2023/7/29 22:17
* @description:
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class PhoneType implements Serializable {
private static final long serialVersionUID = 1L;
private int type;
public static final PhoneType OPPO = new PhoneType(0);
public static final PhoneType VIVO = new PhoneType(1);
public static void main(String[] args) throws Exception {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream(new File("phoneType.out")));
os.writeObject(PhoneType.OPPO);
os.close();
ObjectInputStream is = new ObjectInputStream(new FileInputStream(new File("phoneType.out")));
PhoneType phoneType = (PhoneType) is.readObject();
System.out.println(phoneType == PhoneType.OPPO); // false
}
}
添加 readResolve 方法:
package com.oppo.serializedemo.pojo.po;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import java.io.*;
/**
* @author: wick
* @date: 2023/7/29 22:17
* @description:
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class PhoneType implements Serializable {
private static final long serialVersionUID = 1L;
private int type;
public static final PhoneType OPPO = new PhoneType(0);
public static final PhoneType VIVO = new PhoneType(1);
private Object readResolve() throws ObjectStreamException {
if (type == 0) {
return OPPO;
} else if (type == 1) {
return VIVO;
}
return null;
}
public static void main(String[] args) throws Exception {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream(new File("phoneType.out")));
os.writeObject(PhoneType.OPPO);
os.close();
ObjectInputStream is = new ObjectInputStream(new FileInputStream(new File("phoneType.out")));
PhoneType phoneType = (PhoneType) is.readObject();
System.out.println(phoneType == PhoneType.OPPO); // true
}
}
7.5 数据校验
Java序列化机制在反序列化时支持对数据进行校验。这是因为Java序列化后的数据是明文形式,有可能被修改。在反序列化过程中,为了安全起见,可以对读取到的数据进行校验。默认的Java反序列化是不会校验数据的。 使用数据校验特性,需要让自定义的序列化类实现 java.io.ObjectInputValidation 接口,通过调用回调函数 validateObject 来实现数据验证。此处给出示例
package com.oppo.serializedemo.pojo.po;
import lombok.*;
import java.io.*;
import java.util.Objects;
/**
* @author: wick
* @date: 2023/7/30 10:45
* @description:
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class User implements Serializable, ObjectInputValidation {
private static final long serialVersionUID = 1L;
private String name;
@Override
public void validateObject() throws InvalidObjectException {
if (Objects.equals(name, "zhangSan")) {
throw new InvalidObjectException("用户已经被禁用");
}
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject(); // 执行默认的反序列化操作
validateObject(); // 在反序列化完成后进行对象验证
}
public static void main(String[] args) throws Exception {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("user"));
User user = new User("zhangSan");
os.writeObject(user);
os.close();
ObjectInputStream is = new ObjectInputStream(new FileInputStream("user"));
// 在此处就会抛出异常:java.io.InvalidObjectException: 用户已经被禁用
User user1 = (User) is.readObject();
is.close();
System.out.println(user1);
}
}
8 选择 Serializable 还是 Externalizable
在Java序列化应用方面,读者应该会困惑两种机制应选择哪种。从功能角度看,二者都是Java序列化已经支持的。从易用性方面来考虑,Serializable比Externalizable易用性好。首先,Serializable提供了默认的序列化与反序列化行为,用户不需要关注序列化的实现细节即可拿来使用;而Externalizable必须实现readExternal和writeExternal接口且要提供默认构造函数。其次,在自定义序列化行为方面,Serializable也可以通过readObject和writeObject来支持。 对于初学者或者对自己代码水平没啥自信的同学,可以优先选择Serializable。从很多JDK源码和开源代码中可以看到,序列化接口都实现自Serializable。在继承链路上,如果要终止一个子类的Serializable或者Externaizable特性,则在readObject/writeObject方法或readExternal/writeExternal方法接口里抛出 UnsupportedOperationException 异常,表示不支持序列化和反序列化功能。
9. Java序列化安全
Java序列化后的数据是明文形式,而且数据的组成格式有明确的规律。当这些数据脱离Java安全体系存在磁盘中时,可以通过二进制数编辑工具查看,甚至修改。如果这些数据注入了病毒,应用程序的表现行为将无法预计。为了保障数据的安全性,引入SealedObject和SignedObject对序列化数据进行加密。
9.1 SealedObject
以下演示如何使用 SealedObject 来保证序列化/反序列化安全
package com.oppo.serializedemo.pojo.po;
import lombok.*;
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SealedObject;
import javax.crypto.SecretKey;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/**
* @author: wick
* @date: 2023/7/30 10:45
* @description:
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
public static void main(String[] args) throws Exception {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("user"));
SecretKey key = KeyGenerator.getInstance("DESede").generateKey();
Cipher cipher = Cipher.getInstance("DESede");
cipher.init(Cipher.ENCRYPT_MODE, key);
User user = new User("zhangSan", 18);
SealedObject sealedObject = new SealedObject(user, cipher);
os.writeObject(sealedObject);
os.close();
}
}
使用二进制工具查看 user 文件,发现跟我们之前未加密的数据不一样,连基本字段和值都看不到了
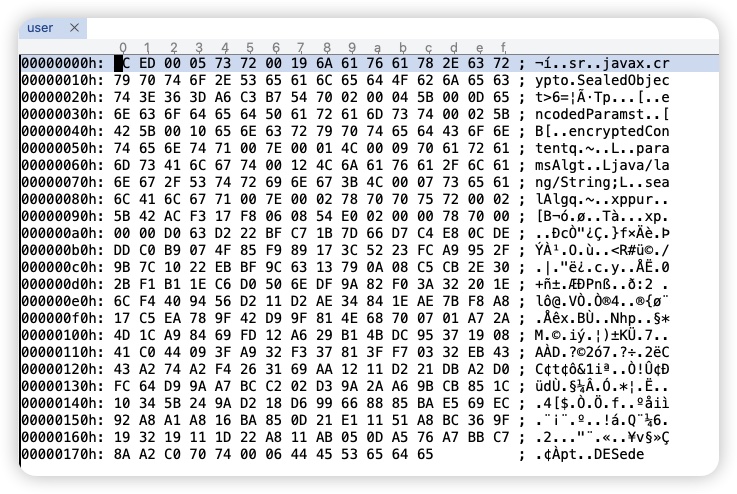
我们直接使用 ObjectInputStream 反序列化一下试试
package com.oppo.serializedemo.pojo.po;
import lombok.*;
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SealedObject;
import javax.crypto.SecretKey;
import java.io.*;
/**
* @author: wick
* @date: 2023/7/30 10:45
* @description:
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
public static void main(String[] args) throws Exception {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("user"));
SecretKey key = KeyGenerator.getInstance("DESede").generateKey();
Cipher cipher = Cipher.getInstance("DESede");
cipher.init(Cipher.ENCRYPT_MODE, key);
User user = new User("zhangSan", 18);
SealedObject sealedObject = new SealedObject(user, cipher);
os.writeObject(sealedObject);
os.close();
ObjectInputStream is = new ObjectInputStream(new FileInputStream("user"));
SealedObject sealedObject1 = (SealedObject) is.readObject();
is.close();
User u1 = (User) sealedObject1.getObject(key);
System.out.println(u1); // User(name=zhangSan, age=18)
}
}
至此,我们就通过一个加密/解密的手段来保护了对象在序列化/反序列化过程中的安全。
9.2 SignedObject
SignedObject 也是通过加解密的方式来保护序列化安全的,示例如下:
package com.oppo.serializedemo.pojo.po;
import lombok.*;
import java.io.*;
import java.security.KeyPair;
import java.security.KeyPairGenerator;
import java.security.Signature;
import java.security.SignedObject;
/**
* @author: wick
* @date: 2023/7/30 11:26
* @description:
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Account implements Serializable {
private String name;
private Double money;
public static void main(String[] args) throws Exception {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("account"));
KeyPair keyPair = KeyPairGenerator.getInstance("RSA").generateKeyPair();
Account account = new Account("zhangSan", 1000.0);
SignedObject signedObject = new SignedObject(account, keyPair.getPrivate(), Signature.getInstance("SHA256withRSA"));
os.writeObject(signedObject);
os.close();
ObjectInputStream is = new ObjectInputStream(new FileInputStream("account"));
SignedObject signedObject1 = (SignedObject) is.readObject();
Account account1 = (Account) signedObject1.getObject();
System.out.println(account1);
}
}
10. 总结
Java序列化方案成熟度高,但性能和压缩效果均一般,只适合JVM系列语言共享数据,不具备完全的跨语言能力。另外,它会带来一些数据安全性和完整性问题。在我们真正的 web 开发过程中,基本不会去使用以上的序列化方式,而是往往会选择具有跨语言能力、性能高效、压缩效果显著的方案,例如Thrift、Protocol Buffer、Json、Xml 等。但是了解 Java 的序列化/反序列化过程,对于程序员能力的提升,还是有较大的意义。