前言
其实想写这篇文很久了……
从毕业实习接触 Rails 到现在两年多了。一开始是基于 Rails 框架来给 Android 客户端提供 API 接口,后来也尝试在 Rails 上倒腾了一些前端的东西,说从 Rails 中受益匪浅是一点都不夸张的。
Ruby On Rails 作为经典的 MVC 框架,在前端领域有着自己独到的见解,在学习的过程中也不断的让我反思自己曾经信奉的那些东西是否过于片面。
本文将简单的分享 Rails 框架的前端技术发展历程,亦是对自己摸索的总结,在这之前有一点很重要那就是:本文没有战争。
当我们今天谈论起前端,我们更多的是在谈论什么?
试想一个问题:如果今天有两位前端工程师碰面,他们大概会聊什么?
我的脑子里很快浮现出一些关键字:vue, react, angular, webpack, vite, redux, 跨平台,小程序,组件化,工程化,微前端……
相信对于大部分前端工程师来说,我们工作的每一天都在使用或者探讨这些东西。
不难发现,这些东西的背后有着一个很基本的共同逻辑:如何更好的基于 JavaScript 来完成页面的构建。
于是我们推导出一个结论——当今天我们聊起前端,我们更多的是在谈论以 JS Render 为基础的技术体系。
于是问题来了……我们真的只有 JS Render 吗?
让我们简单的过一下前端技术发展经历的几个比较典型的阶段:
MVC时代,通过服务端语言开发的模板引擎,动态,快速的生成HTML页面。关键字:JSP,ASP等。- 优点:开发效率高,复杂程度低。
- 缺点:结构混乱,交互体验差,分工不明确。
AJAX时代,通过AJAX显著改善了交互的问题,初显分离之态。关键字:AJXA,JQuery等。- 优点:交互效果显著改善。
- 缺点:依赖
JavaScript带来了大量的兼容问题和性能问题,以及代码结构依然混乱,且大量依赖于AJAX实现的页面出现了SEO问题。
SPA时代,通过JavaScript实现的渲染引擎,直接由JS完成页面的渲染,前后端完全分离。关键字:vue,react,ajax, 前后端分离等。- 优点:富客户端,交互效果起飞,以工程化的方式解决了代码混乱的问题,人员分工明确。
- 缺点:依然没有解决
JavaScript带来的兼容问题与SEO问题,同时渲染引擎加入了渲染生命周期,以及各种数据抽象层提高了编码的心智负担。
以上的列举不算特别完整和严谨,但大体上能够说明前端技术发展历程的主要思路中,有两个比较重要的点:
- 如何更高效的组织代码,解决代码结构混乱的问题。
- 如何解决用户体验差的问题。
而此时,我们就不得不回过头来简单的探讨一下过去的 MVC 架构下的前端到底是怎样的了。
MVC下的前端开发是什么样子?
相信说到 MVC 架构下的前端开发,不少经验丰富的前端工程师会有一些久远的回忆,一些刻板印象涌上心头:
- 开发时
HTML与服务端语言混编。 - 稍微复杂的需求需要编写大量
DOM操作来实现。 - 交互体验差,每一次换页都需要重新加载服务端资源。
- ……
以 Rails 为例,MVC 的 View 层通常使用模板引擎技术来实现快速生成 HTML, 其工作原理很简单,既通过服务端语言来组合 HTML 片段,例如下面的代码是一种名为 erb 的模板引擎,它通过 Ruby 来生成一段列表标签。
<ul>
<%- @books.map do |book| %>
<li><%= book[:name] %></li>
<%- end %>
</ul>
最终得到的 HTML 被发送给浏览器端,渲染出结果:

我们同样可以为这样的结构编写 CSS, JavaScript,但就像传统的静态页一样,我们只能在每一个页面单独的引入该页面要使用的 CSS 与 JavaScript 文件,且在缺乏构建工具的情况下,我们将无缘使用 Less, Sass 等预处理技术。
最终当我们完成代码的编写后,它可能看起来就像这样:
而其交互体验可能就像这样:
正如前面所说,这样的项目有几个很要命的问题:
- 代码结构的问题:模板引擎的语法并不完全与
HTML一致,最好的例子就是上面的HAML。同时由于混杂了大量的服务端逻辑,它要求开发人员需要对后端逻辑有一定的了解。 - 交互体验的问题:传统的
MVC在访问链接,提交表单时,往往伴随浏览器的刷新行为,而每一次刷新都会导致浏览器重新拉取资源与页面渲染,交互体验极差。 - 分工不明确,事实上从模板引擎的角度来看,能够更好完成编码的反而是更熟悉服务端开发的人员,并非以编写页面为擅长的前端开发人员。
- 缺少必要的构建工具,没有办法使用更高效的开发技术如
Sass,ECMAScript的部分新特性。 - 资源管理不合理,需要多次重复拉取相同的资源文件。
站在今天的视角我们很容易理解这些问题,也能很容易想到对策。
而站在产品和用户体验的角度,我们首先要解决的是交互部分的问题,让页面无刷新更新最简单的方法就是 AJAX 。
AJAX: 通过局部刷新来提升用户体验
AJAX 可以帮助我们在不刷新浏览器的情况下完成局部更新,实现更高效可用的交互。AJAX 作为一项成熟的技术发展已经接近 20 年了,这里不再进行赘述了。
简单看一下通过 AJAX 改造前后的页面跳转效果
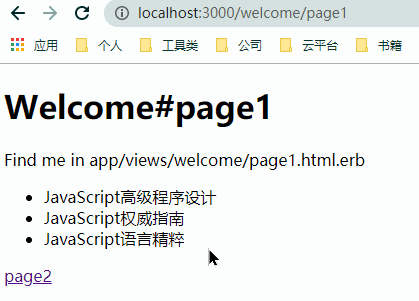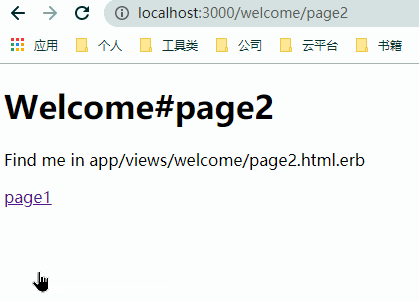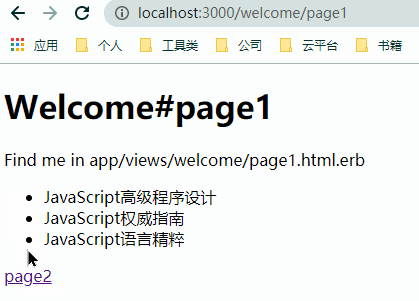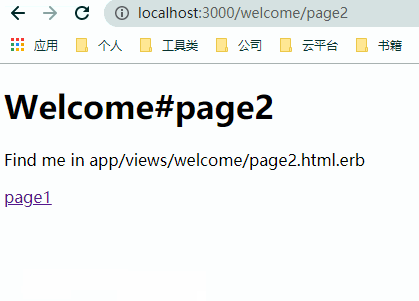
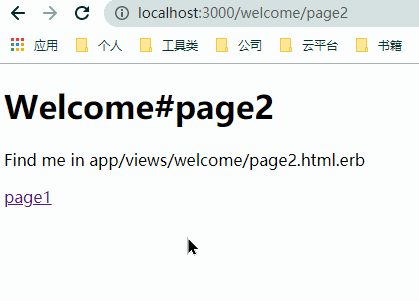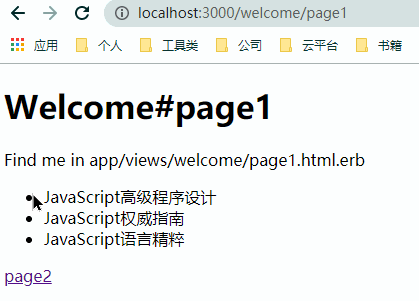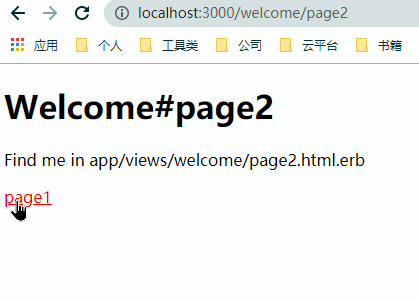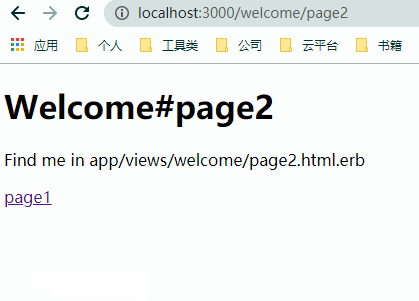
但 AJAX 的引入并不是没有代价的,完全依靠 AJAX 来动态更新的数据没有办法获得 SEO 的支持。同时使用 AJAX 意味着需要编写些许的 JavaScript 代码来完成 DOM 节点的更新操作。另一个更复杂的问题在于,当我们期望通过 AJAX 来完成整个应用的无刷新换页、提交时,意味着我们有大量的 HTML 会在 JavaScript 中动态的插入,即由此来完成页面的局部刷新。此时,代码的可维护性大大的降低,最终化为一头失控的猛兽。
难道我们一定要在完全由 JS Redner 的环境里才能实现浏览器的无缝刷新吗?其实不然。
Turbolinks:PJAX的魔法
Rails 在 4.0 版本默认引入了一个扩展—— Turbolinks。
Turbolinks 是一个轻量,但略带侵略性的 JavaScript 库。关于它的一切,其实要从更早的一项技术说起——PJAX.
PJAX 是一项简单易懂却很有效的技术,在它的 GitHub 页上有这样的介绍:PJAX = AJAX + pushState.
其工作原理很简单:
- 当在页面中点击一个
a标签,或提交form表单时,并非以浏览器的默认行为进行跳转或提交,而是以xhr的方式请求目标地址。 - 服务端在完成请求的处理后,依然基于模板引擎的技术返回渲染完成后的静态
HTML片段。 - 将服务端返回的
HTML片段替换到当前页面的指定位置。 - 使用
history.pushState更新浏览器当前的URL以正常维护浏览器的地址栏。
PJAX 将上述的步骤封装为一个方法,开发者可以快速的实现指定节点的局部渲染:
$(document).pjax('a', '#pjax-container');
整理一下思路,看似无奇的操作背后隐藏着哪些细节:
- 可以有选择的替换页面的部分标签或全部标签来实现局部刷新。
- 由于指向的超链接本质上依然返回
HTML, 因而不影响SEO效果。 - 由于返回的部分会被更新到视图中,因而服务端在
PJAX请求的页面应当仅返回HTML片段而非完整的HTML页。
Turbolinks 是 Rails 基于 PJAX 的再实现,它吸取了 PJAX 的思路,同时还做出了改进和扩展。
相比 PJAX 中隐式的条件需要调整服务端渲染的片段,Turbolinks 更加大胆的选择了让服务端照常返回完整的 HTML 页,而后在本地对页面的 head 标签进行合并,同时将 body 标签完整的替换到当前页面以实现页面的无缝刷新。
这样做的第一大好处是,当应用运行在不支持 history.pushState 的环境时,由于服务端照常返回了完整的页面,可以实现优雅降级,浏览器依然能够正常的加载页面。
第二大好处在于,在这种策略之下 Turbolink 不需要开发者手动的指定节点进行局部渲染,一经安装,整个应用都自动实现了无缝刷新。
第三大好处,Turbolinks 合并的 head 标签中,不会拉取重复的资源,减少了资源文件的重复加载。
除此之外 Turbolinks 还扩充了部分功能,其中比较典型的包括:
- 在页面加载完成后,通过
Node.cloneNode()来缓存页面,使得在网络断开期间也能访问已经缓存的页面。 - 在
Turbolinks换页期间维护了一个内部的进度条用来向用户展示loading状态,与其它的特性相同,它不需要用户编写任何额外的代码。
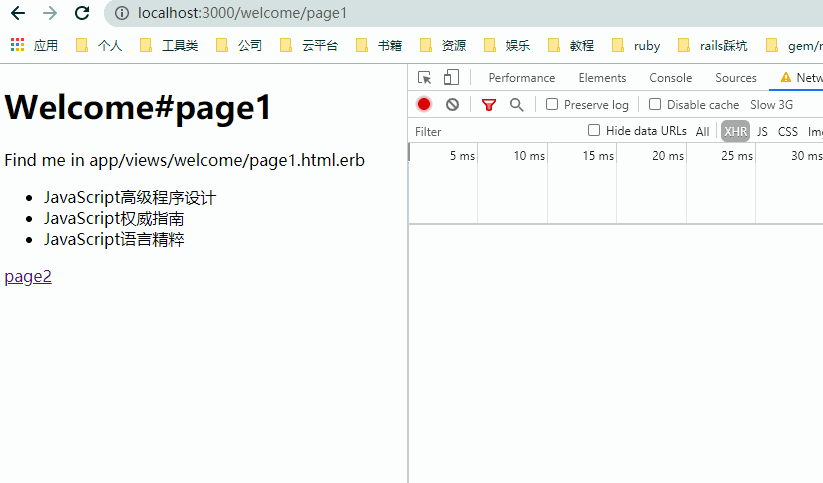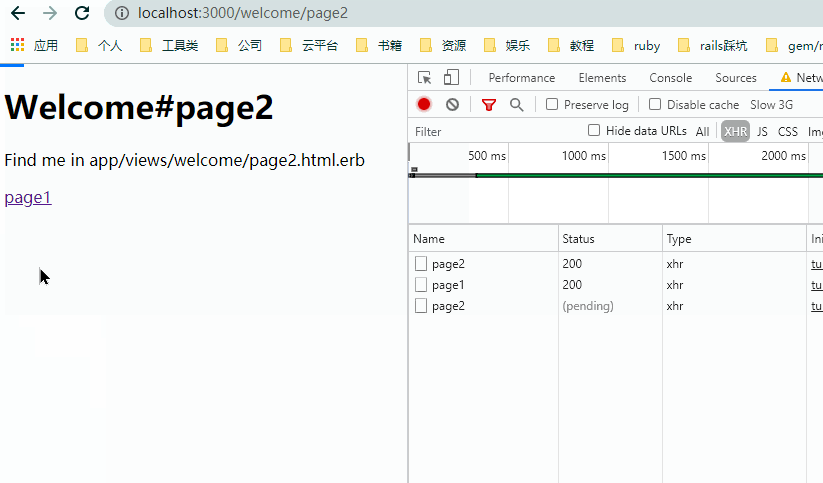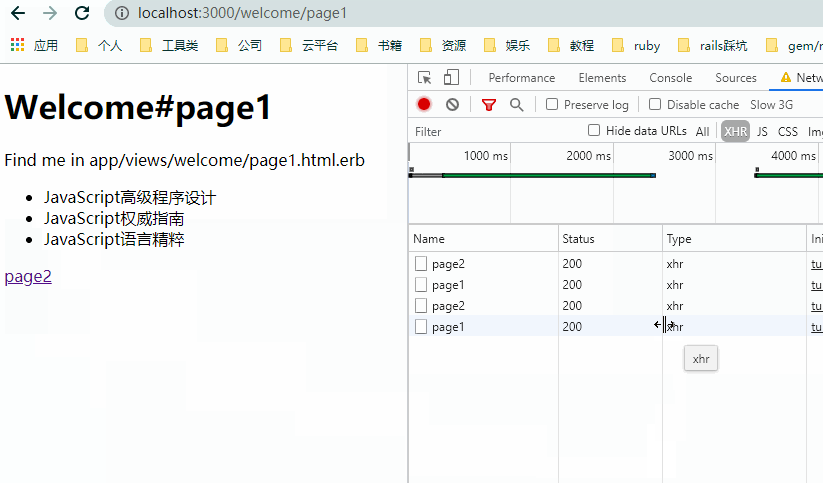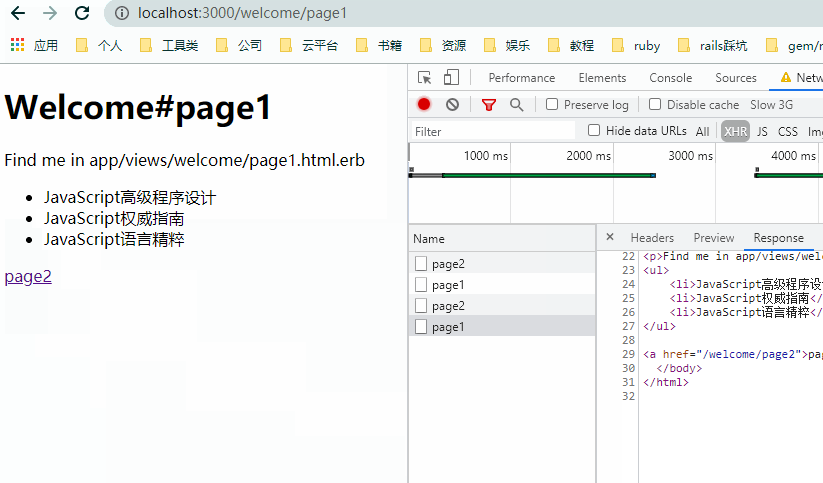
观察上图,注意几个细节:
- 点击链接时,浏览器并没有刷新。
- 页面更新前后浏览器顶部自己维护了加载的进度条。
- 页面切换时,
NetWork里实际发送的是xhr类型的请求。 - 请求返回的是完整的
HTML页。
总结一下,Turbolinks 是一个吸收了 PJAX 思路,以最低成本实现更高交互的轻量级 JavaScript 库。
说完了 Turbolinks 的优点,我们还得说一说 Turbolinks 的缺点,毕竟没有哪一项技术是完美的。
Turbolinks 的存在的第一个问题,由 PJAX 继承而来,且由于 Turbolinks 机制上的改进,这个问题被更加放大。当节点被动态添加至页面时,有一个我们不得不注意到一个问题:已经注册的 JavaScript 事件如何处理?
在使用 PJAX 的时候,我们仅添加片段到页面中,并不太会经常出现需要给这些节点添加移出事件的情况。而当整个页面都被替换掉的时候,问题就变得突出了,其问题具体来说体现在:当页面被替换后,由于浏览器没有刷新,当前页面注册的事件、设置的定时器等均依然有效,相对来说下一个页面渲染时的环境并不纯净。此时如果某一个行为触发了上一个页面的事件,则会产生不可预期的影响。另一层考虑则是这些反复留存下来的事件本质上也会造成内存泄露。
解决这一问题的方法从整体思路上说是统一的,既使操作幂等。
Turbolinks 提供了换页生命周期的钩子函数,使得可以在换页后做一些事情:
document.addEventListener("turbolinks:load", function() {
// ...
})
请注意,正是由于页面的生命周期发生了变化,实际由 Turbolinks 维护的页面只会执行一次 DOMContentLoaded 事件,因而如果期望某一行为始终在页面加载后执行,则应该使用 turbolinks:load 来替换 onload, DOMContentLoaded 事件。
解决上述问题具体的方式包括:
- 在
Turbolinks对应的生命周期里挂载和移除事件,计时器等。 - 使用事件委托,本质依然是幂等,只当节点存在时触发事件。
- 见下文。
另外,Turbolinks 还存在的另一个问题则来源于 addEventListener 方法,在多次换页过程中触发的 document.addEventListener 会反复添加事件监听,这样会导致换页后依然能够执行上一个页面 turbolinks:load 生命周期里的内容。此时,生命周期内的操作幂等性就变得更加重要了。
Turbolinks Prefetch:预加载的新思路
当提到 Turbolinks 时,有一个相关衍生的生态组件就不得不拿出来聊一聊了——Turbolink Prefetch。
正如 Prefetch 这个名字一样,Turbolinks Prefetch 会进行预加载操作以提升页面的访问速度,其原理实际是一种叫做 InstantClick 技术。主要原理为:当用户鼠标置于链接上时,提前拉取目标地址的页面并缓存,当用户点击鼠标时直接从缓存中读取该页面。
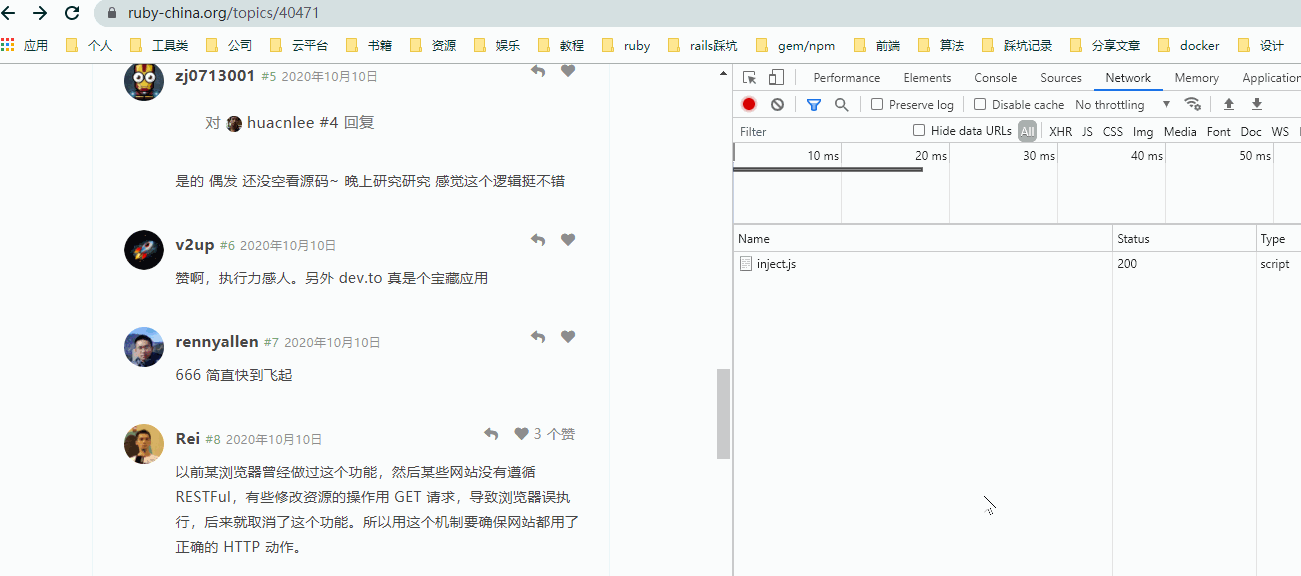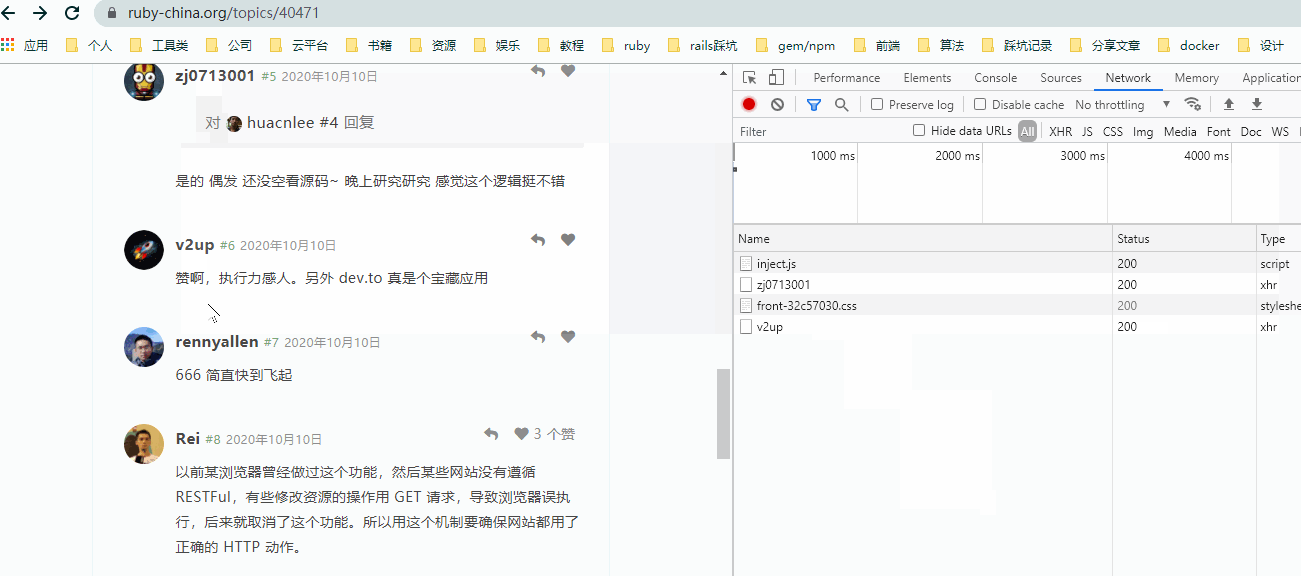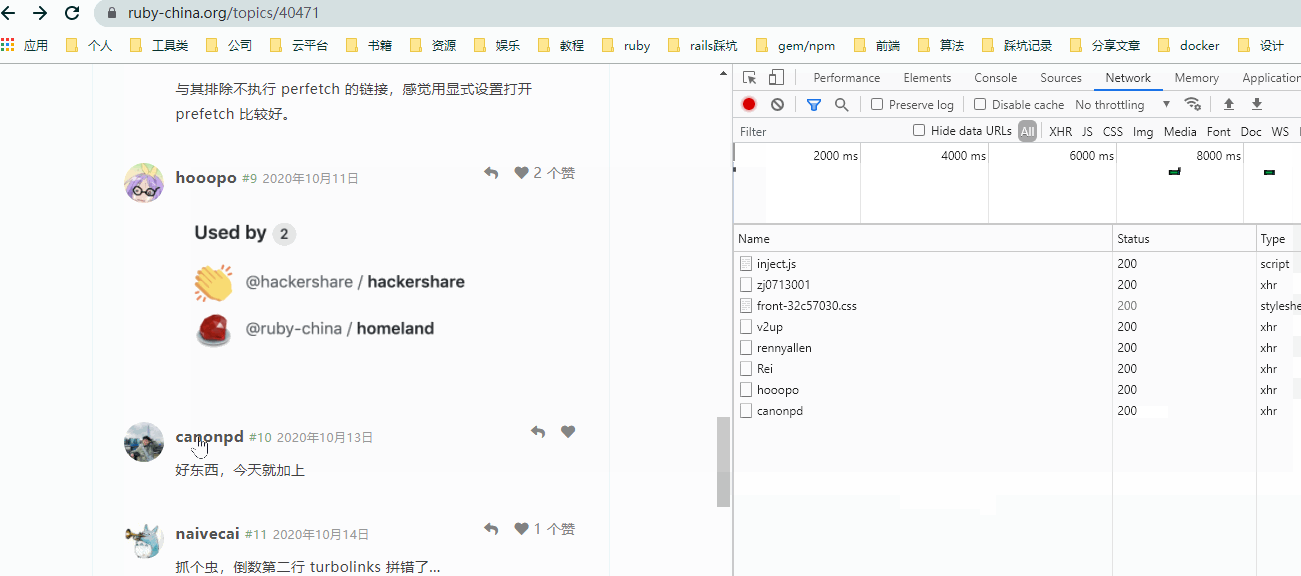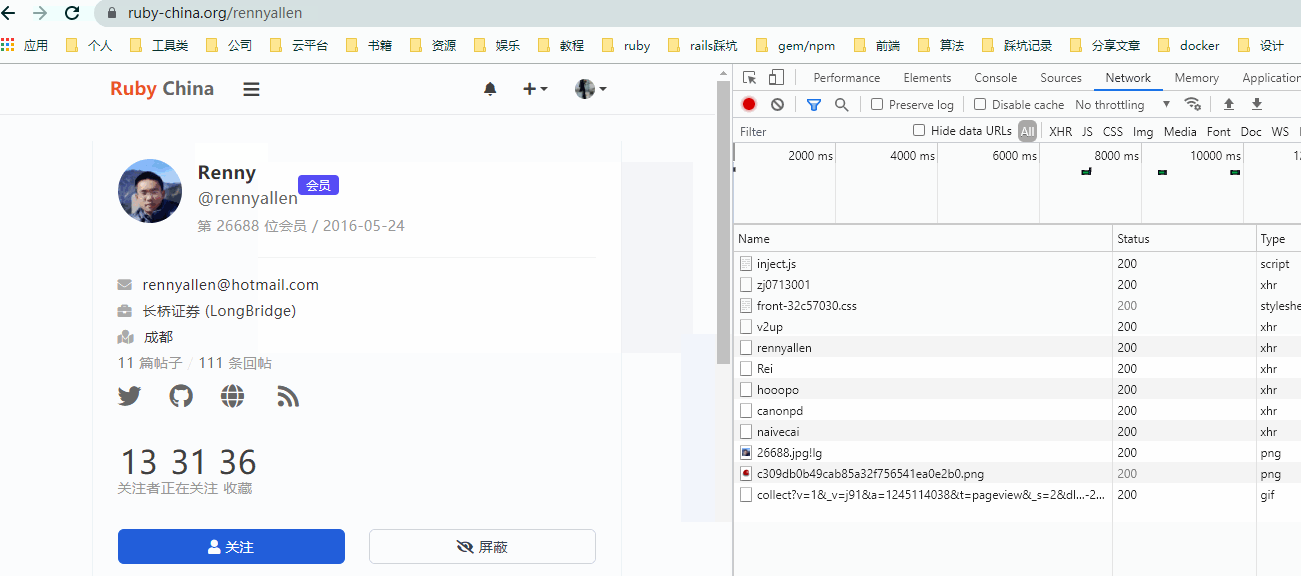
观察上图:
- 当鼠标经过部分链接时,观察
NetWork自动发送了请求。 - 往上滚动时,虽然鼠标再次经过重复的链接,单并没有重复发送请求。
- 点击已请求过的链接,
NetWork并没有发送其它请求,仅在页面加载后请求了页面上的资源文件。 - 与前面
Turbolinks的演示相同,对页面的请求依然使用使用的是xhr方式。
虽然从技术角度来说,借助 Turbolinks 已有的缓存机制实现这一功能似乎并没有什么太大的难度,但我认为这样的思路却非常值得学习:即利用用户的碎片时间提前拉取资源以减少用户的等待时间。从目前来看,这一思路在混合 APP 实现 WebView 秒开时起到了非常不错的效果。
Assets Pipeline:Rails 自己的构建工具
在我们谈论 MVC 下实现的前端有哪些问题时,提到了这样几个问题:
- 缺少必要的构建工具,没有办法使用更高效的开发技术如 Sass,ECMAScript 的部分新特性。
- 资源管理不合理,需要多次重复拉取相同的资源文件。
- ……
前面所介绍的 Turbolinks,Turbolinks Prefetch 等均是来自于交互方面的优化。而上面这些问题则指向了构建工具这一话题。
在今天,当我们开发完成一个前端项目,通常进入生产环境前需要对源代码进行一系列的操作,它们包括:
- 编译代码,把
Sass,Less, 以及高版本的ECMAScript等非浏览器可以直接执行的内容编译成低版本代码或原生代码; - 压缩代码,去除代码中不必要的换行,注释等,减少文件体积;
- 混淆代码,将
JS代码编译为不可读的丑化代码,进一步缩减文件体积; - 合并文件,减少
HTTP请求次数; - 通过摘要算法计算
Hash作为静态资源文件的文件名,使资源可以根据文件内容的变化来合理利用浏览器缓存;
而实现这些操作则需要依赖构建工具,比较有名的就是大家都熟悉的 webpack。
实际上,Rails 在很早就提供了这样一套框架用于静态资源的构建和管理——Assets Pipeline。
放在今天,我们以一名前端工程师的视角来看 Assets Pipeline 其实是非常容易理解的。它主要利用 Sprockets 这一构建工具来实现了上面描述静态资源压缩,,使得在 MVC 的结构下一样可以合理,优雅的管理前端资源。
同时 Assets Pipeline 还自带了 Sass, CoffeeScript 这些从 Ruby 社区孵化出的前端技术的支持。其中 Sass 提高了编写 CSS 的效率。而 CoffeeScript 则为 ES5 添加了诸多有用的语法扩展。如此,在 MVC 结构下也能获得良好的开发体验。
注意一个细节:Assets Pipeline 在进行生产环境的预编译行为时,本质上与现在我们运行 npm run build 使用 webpack 进行打包有着非常大的相似之处。不同之处在于,Rails MVC 下的前端开发并不会依赖 JS Render ,由此导致现代前端基于 webpack 构建的静态资源和 Rails 基于 Assets Pipeline 构建的静态资源在体积上有着量级的区别。
正是得益于这种技术栈不依赖 JS 构建页面,Assets Pipeline 可以放心大胆的将静态资源合并为一个单文件而不用担心体积过大造成资源加载慢的问题。
因而当我们查看一个 Rails 传统技术开发的网站,会发现它仅在浏览器第一次加载页面时,完整的拉取脚本与样式文件,而后在 Turbolinks 启动后,每一次换页都不会也无需拉取静态资源文件,而是仅获取需要显示的 HTML 内容。
有一个非常有意思的点:我们的站点在用户交互上与 SPA 一样在首屏拉取资源,也像 SPA 一样在无缝换页。
UJS:使用非侵入式的 JavaScript 缩减重复代码
除了引入完整的构建体系以外,其实 Rails 还做有一个较为有趣的前端构建技术名为 UJS,它是 Unobtrusive JavaScript 的缩写,翻译为中文为 “非侵入式 JavaScript”。
UJS 本是指将 JS 与页面结构分离的代码风格,而 Rails UJS 只是基于这样一种风格编码的前端工具库,整个扩展仅有 700+ 行代码。
Rails UJS 内部实现了前面我们在 PJAX 和 Turbolinks 里提到的让 a 标签和 form 表单自动使用 xhr 提交的方法,但它并没有针对这一行为做后续的操作,而是提供了对应的事件回调。即是说,开发人员可以自由的设置某一个 a 标签或 form 表单为 xhr 提交,而需要做的仅仅是在该标签上增加一个 data-remote=true 属性,而后即可在回调中拿到对应的请求值。
对比一下使用原生与使用 Rails UJS 实现表单 xhr 提交的代码
// 原生
let form = document.querySelector("form");
form.onsubmit = function (e) {
e.preventDefault();
//阻止submit默认提交行为
let fd = new FormData(form);
fd.append('userId', '1008611');
let xhr = new XMLHttpRequest();
xhr.open("POST","http://www.xxx/api/xxx");
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
console.log(xhr.responseText)
}
}
xhr.send(fd);
}
// 使用 rails_ujs
// 需要在对应的标签上添加 data-remote=true 就像
// <form data-remote="true" id="remoteForm" action="/welcome/test_render">...</form>
document.querySelector("#remoteLink").addEventListener('ajax:success', function (xhr, status, err) {
console.log(xhr, status, err);
});
可以看到代码会简洁很多。
除此之外,Rails UJS 也支持了更多的 xhr 参数如 method 等,使得我们基于这种方式来构建 xhr 变的更快更高效,减少了大量的重复代码。
另一个有趣的用法是,在通过 xhr 请求时,由服务端渲染一段 JavaScript,可以很高效的实现一些交互逻辑。但由于这种方式不便于组织 JS 代码文件,此处不过多展开,详情可以读扩展阅读《Rails 用 RJS 简单有效的实现页面局部刷新》。
Stimulus:Turbolinks 幂等问题的最终解?
Turbolinks 为我们提供了基本的页面交互 SPA 化的解决方案,使我们能以非常轻量的方式来实现一个体验极佳的站点。
Assets Pipeline 为我们带来的构建手段。
Rails UJS 简化了我们构建 AJAX 交互的代码量。
但站在今天的角度来看,似乎编码体验上并没有太大的改进。我们依然在重复的码着 JQuery,我们也依然在重复的操作 DOM,甚至对于如何复用一个页面组件,我们依然没有一个合适的方式。与此同时,引入的 Turbolinks 带来了新的负担,编写 JS 代码的时候我们需要更加注意幂等性……
当我们开始思考这样的问题的时候,Stimulus 来了。
Stimulus 同样是一个轻量的前端库,它通过 H5 的 Mutation Observer 这一特性彻底解决了 Turbolinks 幂等的问题。
Mutation Observer 可以完成 DOM 节点的监听,在 DOM 节点发生变化时,指定对应的逻辑。我们可以通俗的理解这一 API 为原生的 DOM 节点添加了自己的生命周期。
直接看下面的 Stimulus 代码:
import { Controller } from "stimulus"
export default class extends Controller {
static values = { url: String, refreshInterval: Number }
connect() {
this.load()
if (this.hasRefreshIntervalValue) {
this.startRefreshing()
}
}
disconnect() {
this.stopRefreshing()
}
load() {
fetch(this.urlValue)
.then(response => response.text())
.then(html => this.element.innerHTML = html)
}
startRefreshing() {
this.refreshTimer = setInterval(() => {
this.load()
}, this.refreshIntervalValue)
}
stopRefreshing() {
if (this.refreshTimer) {
clearInterval(this.refreshTimer)
}
}
}
我有理由相信写过 vue, react 组件的现代前端工程师可以没有什么压力的阅读这段代码……
Stimulus 通过 data-controller 将逻辑关联到 DOM 节点,同时提供了对应节点的生命周期钩子函数,当节点被渲染后,会触发 connect 方法,而节点被销毁时会触发 disconnect 。同时 Stimulus 还支持定义状态与方法,最终这些内容被合理的挂载到节点的各位置,就像这样:
<div data-controller="content-loader"
data-content-loader-url-value="/messages.html"
data-content-loader-refresh-interval-value="5000"></div>
这一段代码复制于 Stimulus 的文档,它实现了一个可以自动异步加载页面的组件。
由于节点拥有了自己的生命周期,只有当节点真正被渲染在页面上时 Stimulus 才会真正的执行对应的挂载逻辑,因而我们不再需要担心伴随 Turbolinks 的换页带来的事件绑定心智问题。
同时,Stimulus 也完全解决了复用的问题,当需要在另一位置复用这一组件时,我们只需要为该节点添加上对应的 data-controller 属性即可。
最后,Stimulus 通常在单一文件里定义组件,也就是说,基于 Stimulus 开发的应用不会再出现同一个 JS 文件里有成百上千行不知所云毫无关联的 JavaScript 代码的情况。
结语(碎碎念)
其实本来打算再倒腾下 Hotwire 的,但是实在时间有限……
前端是一个大的领域,即使放到一个框架里,内容也是非常多的。
关于 Rails 的前端内容大概就先写到这里了,后面如果有空还会再补充。
最后放上 Ruby China 链接,可以从交互等方面来体验一下,几乎完全与 SPA 类似的交互体验。
hhh如果看完能有所启发那就实在太好啦~
非常赞同~
其实写这篇文章的初衷是这样的:
我自己作为入行没多久的新鸟,在最开始学习 Web 开发的时候,接触到就是各种以 JS 全栈为主的教程和学习路线,所以在相当长的一段时间里我都认为 JavaScript 全栈就是正确的,它不需要理由。
在后来因为一些机遇,实习的时候接触了 Rails,当我越是去尝试了解 Rails 的前端技术栈,便越是发现它并不符合我认知里的“MVC 下 View 层前端开发是落后的前端开发”这一观点。恰恰相反的是,在 Turbolinks,Stimulus 里我看到的是更加理性的前行策略,这使我产生了“JavaScript 全栈真的一定合理吗?我们真的只能用 JavaScript 来写整个页面吗?”的思考。我认为这种理性看待技术发展的思路还是很重要的,今天我也会在 QQ 群里看到类似“什么年代了,还在用 MVC。Vue 不香吗?React不香吗?”的言论,我认为这种思想很要不得,它会让人迷失在对技术的崇拜里,所以我写了这篇文章,希望能够以一种科普(或者说介绍)的视角去促进大家思考那些我们不曾想过的问题,同时也是对我自己学习道路的一种反思。
最后,感谢 dalao 耐心读完并给我反馈~稿子还有一些地方写的不是很清晰,有些思路其实没有表达到,近期还打算再改改。
PS:其实原来还想了解以下 Hotwire 的,最近加班优点严重 (:з)∠),回头再单独写好了 O(∩_∩)O。
目前是个只会用Vue的小白,看完这篇文章拓展了视野,感谢。