HTTP
HTTP的诞生——为知识共享
1989 年 3 月,互联网还只属于少数人。在这一互联网的黎明期, HTTP 诞生了。 CERN(欧洲核子研究组织)的蒂姆 · 伯纳斯 - 李(Tim BernersLee) 博士提出了一种能让远隔两地的研究者们共享知识的设想。 最初设想的基本理念是:借助多文档之间相互关联形成的超文本 (HyperText),连成可相互参阅的 WWW(World Wide Web,万维 网)。
现在已提出了 3 项 WWW 构建技术,分别是:
- 把 SGML(Standard Generalized Markup Language,标准通用标记语言)作为页面的文本标记语言的 HTML(HyperText Markup Language,超文本标记语言);
- 作为文档传递协议的 HTTP ;
- 指定文档所在地址的 URL(Uniform Resource Locator,统一资源定位符)。
WWW 这一名称,是 Web 浏览器当年用来浏览超文本的客户端应用 程序时的名称。现在则用来表示这一系列的集合,也可简称为 Web。
HTTP的发展历程
| HTTP/0.9 | HTTP/1.0 | HTTP/1.1 | HTTP/2.0 |
|---|---|---|---|
| HTTP 于 1990 年问世。那时的 HTTP 并没有作为正式的标准被建立。 现在的 HTTP 其实含有 HTTP1.0 之前版本的意思,因此被称为 HTTP/0.9。 | HTTP 正式作为标准被公布是在 1996 年的 5 月,版本被命名为 HTTP/1.0,并记载于 RFC1945。虽说是初期标准,但该协议标准至今 仍被广泛使用在服务器端。 | 1997 年 1 月公布的 HTTP/1.1 是目前主流的 HTTP 协议版本。当初的 标准是 RFC2068,之后发布的修订版 RFC2616 就是当前的最新版 本。 | HTTP/2.0是一种安全高效的下一代HTTP传输协议。安全是因为HTTP2.0建立在HTTPS协议的基础上,高效是因为它是通过二进制分帧来进行数据传输。 |
HTTP的报文结构
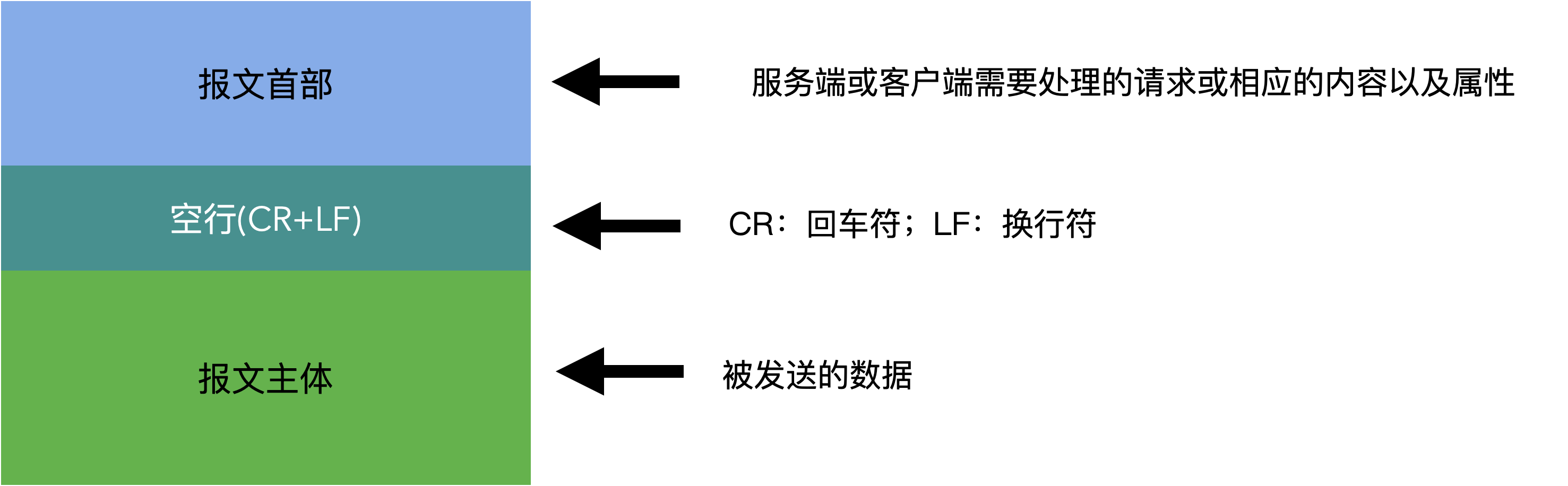
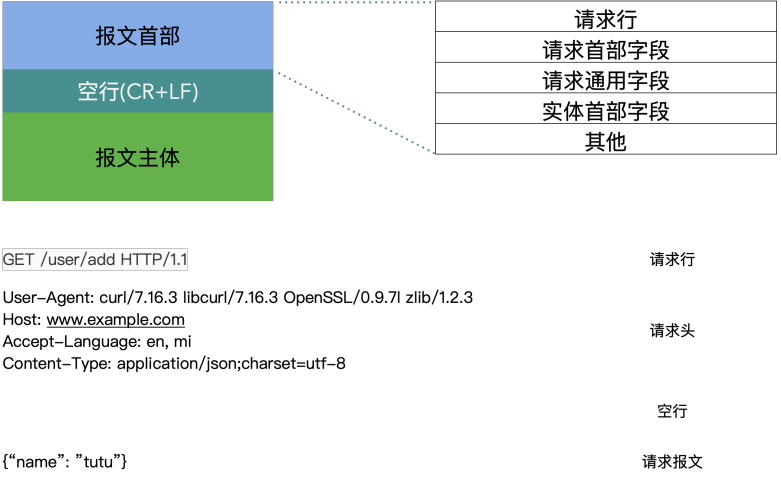
HTTP的报文——请求报文
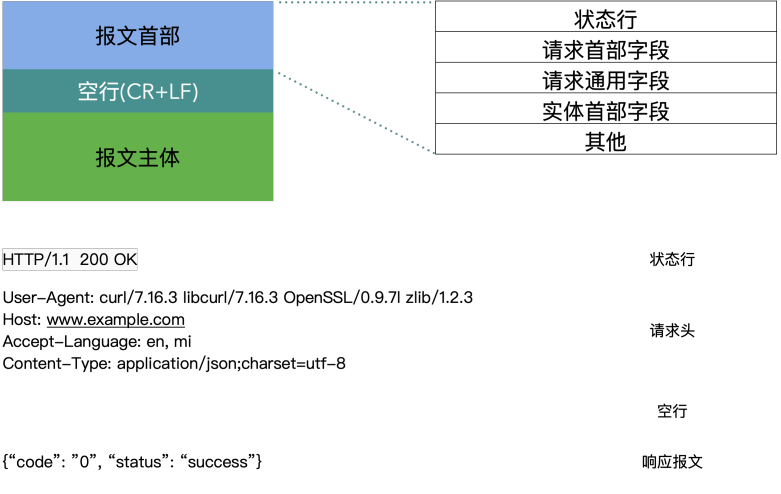
HTTP的报文——响应报文
HTTP中的动词
| GET | POST | PUT | DELETE | HEAD | OPTIONS | TRACE | CONNECT |
|---|---|---|---|---|---|---|---|
| 获取资源,用来请求访问已被URI识别的资源。 | 传输实体主体,虽然GET方法也可以传输实体的主体,但是一般不用,而是使用POST方法。 | 传输文件,但是由于HTTP/1.1协议中的PUT方法自身不带安全机制,因此一般不用此方法,但在一些REST架构的网站,可能会开放PUT方法。 | 删除文件,DELETE 方法用来删除文件,是与 PUT 相反的方法。DELETE 方法按 请求 URI 删除指定的资源。 但是,HTTP/1.1 的 DELETE 方法本身和 PUT 方法一样不带验证机 制,所以一般的 Web 网站也不使用 DELETE 方法。当配合 Web 应用 程序的验证机制,或遵守 REST 标准时还是有可能会开放使用的。 | 获得报文首部,HEAD 方法和 GET 方法一样,只是不返回报文主体部分。用于确认 URI 的有效性及资源更新的日期时间等 | 询问支持的方法,用来查询针对请求 URI 指定的资源支持的方法。 | 追踪路径,客户端通过 TRACE 方法可以查询发送出去的请求是怎样被加工修改 / 篡改的。这是因为,请求想要连接到源目标服务器可能会通过代理 中转,TRACE 方法就是用来确认连接过程中发生的一系列操作。 | 要求用隧道协议连接代理 ,CONNECT 方法要求在与代理服务器通信时建立隧道,实现用隧道协 议进行 TCP 通信。主要使用 SSL(Secure Sockets Layer,安全套接 层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容 加 密后经网络隧道传输。 |
HTTP的状态码
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Information(信息类状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务端错误状态码) | 服务器处理请求出错 |
Requests
Requests简介
Requests是一个基于Urllib3开发的Http库,相对于Urllib3,Requests提供了更为方便的Http请求方式以及以下更为便捷的功能:
- Keep-Alive & 连接池
- 国际化域名和 URL
- 带持久 Cookie 的会话
- 浏览器式的 SSL 认证
- 自动内容解码
- 基本/摘要式的身份认证
- 优雅的 key/value Cookie
- 自动解压
- Unicode 响应体
- HTTP(S) 代理支持
- 文件分块上传
- 流下载
- 连接超时
- 分块请求
- 支持 .netrc
Requests中的Request对象
在requests中,实际发送请求的是request对象,此对象第一个参数就是请求方法,第二个参数为请求的url
from _typeshed import SupportsItems
from typing import Iterable, Optional, Text, Tuple, Union
from .models import Response
from .sessions import _Data
_ParamsMappingKeyType = Union[Text, bytes, int, float]
_ParamsMappingValueType = Union[Text, bytes, int, float, Iterable[Union[Text, bytes, int, float]], None]
def request(method: str, url: str, **kwargs) -> Response: ...
def get(
url: Union[Text, bytes],
params: Optional[
Union[
SupportsItems[_ParamsMappingKeyType, _ParamsMappingValueType],
Tuple[_ParamsMappingKeyType, _ParamsMappingValueType],
Iterable[Tuple[_ParamsMappingKeyType, _ParamsMappingValueType]],
Union[Text, bytes],
]
] = ...,
**kwargs,
) -> Response: ...
def options(url: Union[Text, bytes], **kwargs) -> Response: ...
def head(url: Union[Text, bytes], **kwargs) -> Response: ...
def post(url: Union[Text, bytes], data: _Data = ..., json=..., **kwargs) -> Response: ...
def put(url: Union[Text, bytes], data: _Data = ..., json=..., **kwargs) -> Response: ...
def patch(url: Union[Text, bytes], data: _Data = ..., json=..., **kwargs) -> Response: ...
def delete(url: Union[Text, bytes], **kwargs) -> Response: ...
因此,我们在使用requests库时,除了常见的 requests.get()写法外,还可以看到 requests.request('get')这种写法,其实这两种写法是等价的,接下来让我们看下request这个方法的参数吧
from . import sessions
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
:param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How many seconds to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) Either a boolean, in which case it controls whether we verify
the server's TLS certificate, or a string, in which case it must be a path
to a CA bundle to use. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'https://httpbin.org/get')
>>> req
<Response [200]>
"""
# By using the 'with' statement we are sure the session is closed, thus we
# avoid leaving sockets open which can trigger a ResourceWarning in some
# cases, and look like a memory leak in others.
with sessions.Session() as session:
return session.request(method=method, url=url, **kwargs)
- method: Http请求动词,requests库中封装了 GET, POST, OPTIONS,HEAD,PUTPATCH,DELETE等方法,后面我也会介绍如何定义我们自己的Http动词
- url:请求的url
- params:字典格式的请求参数,比如我们在get请求中的查询参数,就可以使用params参数来传递
- data:字典格式的请求参数,在post请求中,使用form格式提交数据时,就可以使用data参数来传递
- json:在post请求中,使用json格式提交数据时,就可以直接使用json参数来传参,无需再使用json.dumps()先将请求参数序列化再传递
- headers:请求头,字典格式
- cookies:请求的cookies,也是字典格式
- files:当我们需要上传文件时,files参数就派上用场了,在后面的例子中,会介绍如何使用这个参数上传文件
- auth:方便我们使用Http Auth,是一个元组类型
- timeout:设置超时时间用的,当timeout是一个单一的值时,这一 timeout 值将会用作
connect和read二者的 timeout,如果是一个元组,则是分别指定connect和read的时间 - allow_redirects:布尔类型,是否允许自动重定向,默认值为 True
- proxies:字典类型,用来设置代理,在写爬虫时,尤为重要
- verify:布尔类型,是否使用https验证,默认为True
- stream:布尔类型,如果设置为True,则直接返回原始的Response对象,一般用不到,除非你想自己解析。
- cert:设置ssl证书地址,如果本地有ssl证书,则可以使用此参数加载证书,不过一般也用不到。
Requests中的Response对象
在requests中,request方法返回的就是一个Response对象,这个对象包含的参数如下
class Response(object):
"""The :class:`Response <Response>` object, which contains a
server's response to an HTTP request.
"""
__attrs__ = [
'_content', 'status_code', 'headers', 'url', 'history',
'encoding', 'reason', 'cookies', 'elapsed', 'request'
]
- _content:此对象其实会以字节的方式访问请求响应体,当然,最常用的是用来下载文件
- status_code:http状态码
- headers:响应头
- url:请求的url,对于带参数的get请求,如果调用了response.url()则会将查询参数拼接到url后返回
- history:查询此请求的重定向历史,一般用不到,除非你很关心你请求的url是被重定向到了哪里
- encoding:请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问
r.text之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用r.encoding属性来改变它,当然,机智的requests会自动推测编码,一般也不需要我们重新设置编码,相比较urllib3,这个自动推测编码简直良心 - reason:响应HTTP状态的文本原因,一般极少用到
- cookies:cookies,没啥好解释的,就是k-v对
- elapsed:请求和响应的时间差,是的,你没看错,不需要你自己写个装饰器来算时间差来看请求用了多久,requests人家自己有,良心的不行,但是我们依旧很少用到
- request:PreparedRequest对象,这个对象就是requests的核心对象之一后面的源码解析环节,会详细介绍这个对象是如何处理我们上面提到的request参数的
GET请求
使用requests发送带查询参数的get请求时,可以使用 params 参数来传递查询参数,对于
import requests
def send_get_with_params():
"""
发送带参数的get请求
Returns:
"""
parameters = {
"name": "wickTu",
"age": 27,
}
headers = {
"token": "HlOMkoOtQ4ngiLNmChMHeaggoFSgmJ6xKozr08p4NaNsXOkjph7zRFXL9KZqvoQW"
}
response = requests.get(url="http://www.httpbin.org/get", params=parameters, headers=headers)
# 反序列化json,以字典类型输出
print(response.json())
POST请求——data
当我们需要使用form格式提交数据时,则可以使用data来传递参数,其他参数参考《Requests中的Request对象》章节
import requests
def send_post_by_data():
url = "http://www.httpbin.org/post"
payload = {
"name": "wickTu",
"age": 27,
}
resp = requests.request("POST", url=url, data=payload)
print(resp.json())
POST请求——json
当我们需要使用post请求提交json格式的数据时,有以下两种方式可供选择:
# 使用json.dumps()序列化数据后,用data参数提交
def send_post_by_json():
import json
url = "http://www.httpbin.org/post"
payload = {
"name": "wickTu",
"age": 27,
}
resp = requests.request("POST", url=url, data=json.dumps(payload))
print(resp.json())
# 直接使用json参数来提交数据,相比于第一种,更加方便
def send_post_by_json():
url = "http://www.httpbin.org/post"
payload = {
"name": "wickTu",
"age": 27,
}
resp = requests.request("POST", url=url, json=payload)
print(resp.json())
在requests中,json参数的实现原理如下:
def prepare_body(self, data, files, json=None):
"""Prepares the given HTTP body data."""
# Check if file, fo, generator, iterator.
# If not, run through normal process.
# Nottin' on you.
body = None
content_type = None
if not data and json is not None:
# urllib3 requires a bytes-like body. Python 2's json.dumps
# provides this natively, but Python 3 gives a Unicode string.
content_type = 'application/json'
body = complexjson.dumps(json)
if not isinstance(body, bytes):
body = body.encode('utf-8')
其实,json参数,就是使用json模块将数据序列化,然后再进行发送的,所以本质上,以上两种写法是等价的,只是使用json参数更容易让人理解此post请求的数据提交方式,非常人性化。
POST请求——params
params参数除了在get请求中用来添加查询参数,在post请求中也是一样的,如果你有用过postman,在post请求方式中,还有一种请求方式就是 **x-www-form-urlencoded **,在requests中,则可以使用params参数实现此种提交方式,示例代码如下:
import requests
def send_post_by_params():
url = "http://www.httpbin.org/post"
payload = {
"name": "wickTu",
"age": 27,
}
resp = requests.post(url=url, params=payload)
print(resp.json())
POST请求——files
除了以上几种数据提交方式,文件上传也是我们很常见的操作,但是对于requests,当你要上传一个非常大的文件作为 nultipart/form-data 请求时,requests是不支持的,不过好在可以使用第三方包 requests-toolbelt_** **_来实现大文件上传的功能。
# 普通单文件上传
def send_post_by_files():
url = "http://www.httpbin.org/post"
files = {"files": open("./requests_demo.py", 'rb')}
resp = requests.post(url=url, files=files)
print(resp.json())
# 多文件上传
def send_post_by_mulitfiles():
url = "http://www.httpbin.org/post"
files = [
('file1', ('1.png', open('wallhaven-wdfxkr.jpg', 'rb'), 'image/png')),
('file2', ('2.png', open('wallhaven-wyzxkr.jpg', 'rb'), 'image/png'))
]
resp = requests.post(url=url, files=files)
print(resp.json())
# 上传文件时提交其他参数
def send_post_by_mulitfiles_params():
url = "http://www.httpbin.org/post"
data = {
"name": "wickTu",
"age": 23
}
files = [
('file1', ('1.png', open('006bllTKly1fpg2q9wqlwj30k00k074z.jpg', 'rb'), 'image/png')),
('file2', ('2.png', open('006bllTKly1fpg2q9wqlwj30k00k074z.jpg', 'rb'), 'image/png'))
]
resp = requests.post(url=url, files=files, data=data)
print(resp.json())
# 使用requests-toolbelt上传大文件
def send_post_by_large_file():
import requests
from requests_toolbelt import MultipartEncoder
url = "http://www.httpbin.org/post"
m = MultipartEncoder(
fields={'name': 'wickTu', "age": '100',
'file1': ('1.png', open('wallhaven-28ekym.jpg', 'rb'), 'image/png'),
'file2': ('2.png', open('wallhaven-g7jg63.png', 'rb'), 'image/png')}
)
resp = requests.post(url=url, data=m, headers={'Content-Type': m.content_type})
print(resp.json())
会话对象——session
会话对象可以让你跨请求保持某些参数,它也会在同一个session实例发出的所有请求之间保持cookie,其内部是使用urllib3的连接池功能,所以如果我们要向同一个主机发送多个请求,底层的TCP连接会被重用,从而带来显著的性能提升。使用session对象发送请求方式与requests一样,以下是示例代码:
def send_get_by_session():
s = requests.session()
url = "http://www.httpbin.org/get"
payload = {
"name": "wickTu",
"age": 27,
}
resp = s.get(url=url, params=payload)
print(resp.json())
Requests中的PreparedRequest对象
在上面的章节中我们有讲到,其实在我们填好参数,发送请求之前,requests内部会对我们的参数做一次预处理,接下来我会讲这个预处理的过程大致讲解
class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
"""The fully mutable :class:`PreparedRequest <PreparedRequest>` object,
containing the exact bytes that will be sent to the server.
Instances are generated from a :class:`Request <Request>` object, and
should not be instantiated manually; doing so may produce undesirable
effects.
Usage::
>>> import requests
>>> req = requests.Request('GET', 'https://httpbin.org/get')
>>> r = req.prepare()
>>> r
<PreparedRequest [GET]>
>>> s = requests.Session()
>>> s.send(r)
<Response [200]>
"""
def __init__(self):
#: HTTP verb to send to the server.
self.method = None
#: HTTP URL to send the request to.
self.url = None
#: dictionary of HTTP headers.
self.headers = None
# The `CookieJar` used to create the Cookie header will be stored here
# after prepare_cookies is called
self._cookies = None
#: request body to send to the server.
self.body = None
#: dictionary of callback hooks, for internal usage.
self.hooks = default_hooks()
#: integer denoting starting position of a readable file-like body.
self._body_position = None
def prepare(self,
method=None, url=None, headers=None, files=None, data=None,
params=None, auth=None, cookies=None, hooks=None, json=None):
"""Prepares the entire request with the given parameters."""
self.prepare_method(method)
self.prepare_url(url, params)
self.prepare_headers(headers)
self.prepare_cookies(cookies)
self.prepare_body(data, files, json)
self.prepare_auth(auth, url)
# Note that prepare_auth must be last to enable authentication schemes
# such as OAuth to work on a fully prepared request.
# This MUST go after prepare_auth. Authenticators could add a hook
self.prepare_hooks(hooks)
def __repr__(self):
return '<PreparedRequest [%s]>' % (self.method)
def copy(self):
p = PreparedRequest()
p.method = self.method
p.url = self.url
p.headers = self.headers.copy() if self.headers is not None else None
p._cookies = _copy_cookie_jar(self._cookies)
p.body = self.body
p.hooks = self.hooks
p._body_position = self._body_position
return p
def prepare_method(self, method):
"""Prepares the given HTTP method."""
self.method = method
if self.method is not None:
self.method = to_native_string(self.method.upper())
@staticmethod
def _get_idna_encoded_host(host):
import idna
try:
host = idna.encode(host, uts46=True).decode('utf-8')
except idna.IDNAError:
raise UnicodeError
return host
def prepare_url(self, url, params):
"""Prepares the given HTTP URL."""
#: Accept objects that have string representations.
#: We're unable to blindly call unicode/str functions
#: as this will include the bytestring indicator (b'')
#: on python 3.x.
#: https://github.com/psf/requests/pull/2238
if isinstance(url, bytes):
url = url.decode('utf8')
else:
url = unicode(url) if is_py2 else str(url)
# Remove leading whitespaces from url
url = url.lstrip()
# Don't do any URL preparation for non-HTTP schemes like `mailto`,
# `data` etc to work around exceptions from `url_parse`, which
# handles RFC 3986 only.
if ':' in url and not url.lower().startswith('http'):
self.url = url
return
# Support for unicode domain names and paths.
try:
scheme, auth, host, port, path, query, fragment = parse_url(url)
except LocationParseError as e:
raise InvalidURL(*e.args)
if not scheme:
error = ("Invalid URL {0!r}: No schema supplied. Perhaps you meant http://{0}?")
error = error.format(to_native_string(url, 'utf8'))
raise MissingSchema(error)
if not host:
raise InvalidURL("Invalid URL %r: No host supplied" % url)
# In general, we want to try IDNA encoding the hostname if the string contains
# non-ASCII characters. This allows users to automatically get the correct IDNA
# behaviour. For strings containing only ASCII characters, we need to also verify
# it doesn't start with a wildcard (*), before allowing the unencoded hostname.
if not unicode_is_ascii(host):
try:
host = self._get_idna_encoded_host(host)
except UnicodeError:
raise InvalidURL('URL has an invalid label.')
elif host.startswith(u'*'):
raise InvalidURL('URL has an invalid label.')
# Carefully reconstruct the network location
netloc = auth or ''
if netloc:
netloc += '@'
netloc += host
if port:
netloc += ':' + str(port)
# Bare domains aren't valid URLs.
if not path:
path = '/'
if is_py2:
if isinstance(scheme, str):
scheme = scheme.encode('utf-8')
if isinstance(netloc, str):
netloc = netloc.encode('utf-8')
if isinstance(path, str):
path = path.encode('utf-8')
if isinstance(query, str):
query = query.encode('utf-8')
if isinstance(fragment, str):
fragment = fragment.encode('utf-8')
if isinstance(params, (str, bytes)):
params = to_native_string(params)
enc_params = self._encode_params(params)
if enc_params:
if query:
query = '%s&%s' % (query, enc_params)
else:
query = enc_params
url = requote_uri(urlunparse([scheme, netloc, path, None, query, fragment]))
self.url = url
def prepare_headers(self, headers):
"""Prepares the given HTTP headers."""
self.headers = CaseInsensitiveDict()
if headers:
for header in headers.items():
# Raise exception on invalid header value.
check_header_validity(header)
name, value = header
self.headers[to_native_string(name)] = value
def prepare_body(self, data, files, json=None):
"""Prepares the given HTTP body data."""
# Check if file, fo, generator, iterator.
# If not, run through normal process.
# Nottin' on you.
body = None
content_type = None
if not data and json is not None:
# urllib3 requires a bytes-like body. Python 2's json.dumps
# provides this natively, but Python 3 gives a Unicode string.
content_type = 'application/json'
body = complexjson.dumps(json)
if not isinstance(body, bytes):
body = body.encode('utf-8')
is_stream = all([
hasattr(data, '__iter__'),
not isinstance(data, (basestring, list, tuple, Mapping))
])
if is_stream:
try:
length = super_len(data)
except (TypeError, AttributeError, UnsupportedOperation):
length = None
body = data
if getattr(body, 'tell', None) is not None:
# Record the current file position before reading.
# This will allow us to rewind a file in the event
# of a redirect.
try:
self._body_position = body.tell()
except (IOError, OSError):
# This differentiates from None, allowing us to catch
# a failed `tell()` later when trying to rewind the body
self._body_position = object()
if files:
raise NotImplementedError('Streamed bodies and files are mutually exclusive.')
if length:
self.headers['Content-Length'] = builtin_str(length)
else:
self.headers['Transfer-Encoding'] = 'chunked'
else:
# Multi-part file uploads.
if files:
(body, content_type) = self._encode_files(files, data)
else:
if data:
body = self._encode_params(data)
if isinstance(data, basestring) or hasattr(data, 'read'):
content_type = None
else:
content_type = 'application/x-www-form-urlencoded'
self.prepare_content_length(body)
# Add content-type if it wasn't explicitly provided.
if content_type and ('content-type' not in self.headers):
self.headers['Content-Type'] = content_type
self.body = body
def prepare_content_length(self, body):
"""Prepare Content-Length header based on request method and body"""
if body is not None:
length = super_len(body)
if length:
# If length exists, set it. Otherwise, we fallback
# to Transfer-Encoding: chunked.
self.headers['Content-Length'] = builtin_str(length)
elif self.method not in ('GET', 'HEAD') and self.headers.get('Content-Length') is None:
# Set Content-Length to 0 for methods that can have a body
# but don't provide one. (i.e. not GET or HEAD)
self.headers['Content-Length'] = '0'
def prepare_auth(self, auth, url=''):
"""Prepares the given HTTP auth data."""
# If no Auth is explicitly provided, extract it from the URL first.
if auth is None:
url_auth = get_auth_from_url(self.url)
auth = url_auth if any(url_auth) else None
if auth:
if isinstance(auth, tuple) and len(auth) == 2:
# special-case basic HTTP auth
auth = HTTPBasicAuth(*auth)
# Allow auth to make its changes.
r = auth(self)
# Update self to reflect the auth changes.
self.__dict__.update(r.__dict__)
# Recompute Content-Length
self.prepare_content_length(self.body)
def prepare_cookies(self, cookies):
"""Prepares the given HTTP cookie data.
This function eventually generates a ``Cookie`` header from the
given cookies using cookielib. Due to cookielib's design, the header
will not be regenerated if it already exists, meaning this function
can only be called once for the life of the
:class:`PreparedRequest <PreparedRequest>` object. Any subsequent calls
to ``prepare_cookies`` will have no actual effect, unless the "Cookie"
header is removed beforehand.
"""
if isinstance(cookies, cookielib.CookieJar):
self._cookies = cookies
else:
self._cookies = cookiejar_from_dict(cookies)
cookie_header = get_cookie_header(self._cookies, self)
if cookie_header is not None:
self.headers['Cookie'] = cookie_header
def prepare_hooks(self, hooks):
"""Prepares the given hooks."""
# hooks can be passed as None to the prepare method and to this
# method. To prevent iterating over None, simply use an empty list
# if hooks is False-y
hooks = hooks or []
for event in hooks:
self.register_hook(event, hooks[event])
在PreparedRequest对象中,我们添加的请求参数会被做不同的处理,接下来我们逐个分析参数是如何被预处理的
method
_method_参数指定了我们发送请求的方式,其对应的预处理方法为 prepare_method(),核心代码如下:
def prepare_method(self, method):
"""Prepares the given HTTP method."""
self.method = method
if self.method is not None:
self.method = to_native_string(self.method.upper())
def to_native_string(string, encoding='ascii'):
"""Given a string object, regardless of type, returns a representation of
that string in the native string type, encoding and decoding where
necessary. This assumes ASCII unless told otherwise.
"""
if isinstance(string, builtin_str):
out = string
else:
if is_py2:
out = string.encode(encoding)
else:
out = string.decode(encoding)
return out
上面的代码其实很简单,就是将我们传入的methd参数值使用ascii编码为str类型
url
_url_参数指定了我们请求的地址,其对应的预处理方法为 prepare_url(),核心代码如下:
def prepare_url(self, url, params):
"""Prepares the given HTTP URL."""
#: Accept objects that have string representations.
#: We're unable to blindly call unicode/str functions
#: as this will include the bytestring indicator (b'')
#: on python 3.x.
#: https://github.com/psf/requests/pull/2238
if isinstance(url, bytes):
url = url.decode('utf8')
else:
url = unicode(url) if is_py2 else str(url)
# Remove leading whitespaces from url
url = url.lstrip()
# Don't do any URL preparation for non-HTTP schemes like `mailto`,
# `data` etc to work around exceptions from `url_parse`, which
# handles RFC 3986 only.
if ':' in url and not url.lower().startswith('http'):
self.url = url
return
# Support for unicode domain names and paths.
try:
scheme, auth, host, port, path, query, fragment = parse_url(url)
except LocationParseError as e:
raise InvalidURL(*e.args)
if not scheme:
error = ("Invalid URL {0!r}: No schema supplied. Perhaps you meant http://{0}?")
error = error.format(to_native_string(url, 'utf8'))
raise MissingSchema(error)
if not host:
raise InvalidURL("Invalid URL %r: No host supplied" % url)
# In general, we want to try IDNA encoding the hostname if the string contains
# non-ASCII characters. This allows users to automatically get the correct IDNA
# behaviour. For strings containing only ASCII characters, we need to also verify
# it doesn't start with a wildcard (*), before allowing the unencoded hostname.
if not unicode_is_ascii(host):
try:
host = self._get_idna_encoded_host(host)
except UnicodeError:
raise InvalidURL('URL has an invalid label.')
elif host.startswith(u'*'):
raise InvalidURL('URL has an invalid label.')
# Carefully reconstruct the network location
netloc = auth or ''
if netloc:
netloc += '@'
netloc += host
if port:
netloc += ':' + str(port)
# Bare domains aren't valid URLs.
if not path:
path = '/'
if is_py2:
if isinstance(scheme, str):
scheme = scheme.encode('utf-8')
if isinstance(netloc, str):
netloc = netloc.encode('utf-8')
if isinstance(path, str):
path = path.encode('utf-8')
if isinstance(query, str):
query = query.encode('utf-8')
if isinstance(fragment, str):
fragment = fragment.encode('utf-8')
if isinstance(params, (str, bytes)):
params = to_native_string(params)
enc_params = self._encode_params(params)
if enc_params:
if query:
query = '%s&%s' % (query, enc_params)
else:
query = enc_params
url = requote_uri(urlunparse([scheme, netloc, path, None, query, fragment]))
self.url = url
def parse_url(url):
"""
Given a url, return a parsed :class:`.Url` namedtuple. Best-effort is
performed to parse incomplete urls. Fields not provided will be None.
This parser is RFC 3986 compliant.
The parser logic and helper functions are based heavily on
work done in the ``rfc3986`` module.
:param str url: URL to parse into a :class:`.Url` namedtuple.
Partly backwards-compatible with :mod:`urlparse`.
Example::
>>> parse_url('http://google.com/mail/')
Url(scheme='http', host='google.com', port=None, path='/mail/', ...)
>>> parse_url('google.com:80')
Url(scheme=None, host='google.com', port=80, path=None, ...)
>>> parse_url('/foo?bar')
Url(scheme=None, host=None, port=None, path='/foo', query='bar', ...)
"""
if not url:
# Empty
return Url()
source_url = url
if not SCHEME_RE.search(url):
url = "//" + url
try:
scheme, authority, path, query, fragment = URI_RE.match(url).groups()
normalize_uri = scheme is None or scheme.lower() in NORMALIZABLE_SCHEMES
if scheme:
scheme = scheme.lower()
if authority:
auth, host, port = SUBAUTHORITY_RE.match(authority).groups()
if auth and normalize_uri:
auth = _encode_invalid_chars(auth, USERINFO_CHARS)
if port == "":
port = None
else:
auth, host, port = None, None, None
if port is not None:
port = int(port)
if not (0 <= port <= 65535):
raise LocationParseError(url)
host = _normalize_host(host, scheme)
if normalize_uri and path:
path = _remove_path_dot_segments(path)
path = _encode_invalid_chars(path, PATH_CHARS)
if normalize_uri and query:
query = _encode_invalid_chars(query, QUERY_CHARS)
if normalize_uri and fragment:
fragment = _encode_invalid_chars(fragment, FRAGMENT_CHARS)
except (ValueError, AttributeError):
return six.raise_from(LocationParseError(source_url), None)
# For the sake of backwards compatibility we put empty
# string values for path if there are any defined values
# beyond the path in the URL.
# TODO: Remove this when we break backwards compatibility.
if not path:
if query is not None or fragment is not None:
path = ""
else:
path = None
# Ensure that each part of the URL is a `str` for
# backwards compatibility.
if isinstance(url, six.text_type):
ensure_func = six.ensure_text
else:
ensure_func = six.ensure_str
def ensure_type(x):
return x if x is None else ensure_func(x)
return Url(
scheme=ensure_type(scheme),
auth=ensure_type(auth),
host=ensure_type(host),
port=port,
path=ensure_type(path),
query=ensure_type(query),
fragment=ensure_type(fragment),
)
在上述代码中,其实就是对url的格式和每个部分做了检查以及编码处理,一个完整的url其实是由如下部分组成的
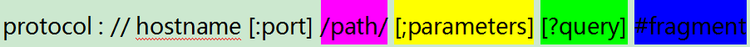
图中中括号是可选项
- protocol 协议,常用的协议是http
- hostname 主机地址,可以是域名,也可以是IP地址
- port 端口 http协议默认端口是:80端口,如果不写默认就是:80端口
- path 路径 网络资源在服务器中的指定路径
- parameters 参数 如果要向服务器传入参数,在这部分输入
- query 查询字符串 如果需要从服务器那里查询内容,在这里编辑
- fragment 片段 网页中可能会分为不同的片段,如果想访问网页后直接到达指定位置,可以在这部分设置
如 http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name 这个url, 我们做以上拆分
- protocol: http
- hostname: www.aspxfans.com
- port: 8080
- path: /news/
- parameters: boardID, ID, page
- fragment: name,其实就是html中的锚点
好了,了解了url的组成,其实上面的代码我们也就很好理解了,在此处就不再赘述了,大家可以自行翻阅源码查看,里面都是很基础的代码。
headers
headers参数指定了我们的请求头,除了HTTP协议中规定的参数外,我们也可以向里面添加我们自定义的内容,比如现在很多系统都是通过token鉴权的,在请求头里面就可以添加自定义参数 Authorization 来带上我们的token,从而完成请求的验证,headers参数对应的预处理方法为 prepare_headers,其核心代码如下:
def prepare_headers(self, headers):
"""Prepares the given HTTP headers."""
self.headers = CaseInsensitiveDict()
if headers:
for header in headers.items():
# Raise exception on invalid header value.
check_header_validity(header)
name, value = header
self.headers[to_native_string(name)] = value
def check_header_validity(header):
"""Verifies that header value is a string which doesn't contain
leading whitespace or return characters. This prevents unintended
header injection.
:param header: tuple, in the format (name, value).
"""
name, value = header
if isinstance(value, bytes):
pat = _CLEAN_HEADER_REGEX_BYTE
else:
pat = _CLEAN_HEADER_REGEX_STR
try:
if not pat.match(value):
raise InvalidHeader("Invalid return character or leading space in header: %s" % name)
except TypeError:
raise InvalidHeader("Value for header {%s: %s} must be of type str or "
"bytes, not %s" % (name, value, type(value)))
上面的代码其实就是对我们添加的请求头内的k-v对做了格式和特殊字符的检查,然后组成一个新的字典,代码很简单,不再赘述。
cookies
cookies一般不是我们在发送请求时主动生成的,但是requests允许我们在发送请求时带上我们手动添加的cookie,从而完成一些鉴权之类的操作,其预处理方法为 prepare_cookies,核心代码如下:
def prepare_cookies(self, cookies):
"""Prepares the given HTTP cookie da
This function eventually generates a ``Cookie`` header from the
given cookies using cookielib. Due to cookielib's design, the header
will not be regenerated if it already exists, meaning this function
can only be called once for the life of the
:class:`PreparedRequest <PreparedRequest>` object. Any subsequent calls
to ``prepare_cookies`` will have no actual effect, unless the "Cookie"
header is removed beforehand.
"""
if isinstance(cookies, cookielib.CookieJar):
self._cookies = cookies
else:
self._cookies = cookiejar_from_dict(cooki
cookie_header = get_cookie_header(self._cookies, self)
if cookie_header is not None:
self.headers['Cookie'] = cookie_header
代码也很简单,就是向headers中加了Cookie这个字段,然后带上我们添加的cookie
body(data, files, json)
大家通过标题可能已经发现了,params参数并不算在body里面,那是因为对于http请求来说,params其实是在url里面的,并不在我们的请求报文中,因此请求报文body只包含了data,files,json这三个参数的内容,其预处理方法为 prepare_body,核心代码如下:
def prepare_body(self, data, files, json=None):
"""Prepares the given HTTP body data."""
# Check if file, fo, generator, iterator.
# If not, run through normal proce
# Nottin' on you.
body = None
content_type = N
if not data and json is not None:
# urllib3 requires a bytes-like body. Python 2's json.dumps
# provides this natively, but Python 3 gives a Unicode string.
content_type = 'application/json'
body = complexjson.dumps(json)
if not isinstance(body, bytes):
body = body.encode('utf-
is_stream = all([
hasattr(data, '__iter__'),
not isinstance(data, (basestring, list, tuple, Mapping))
if is_stream:
try:
length = super_len(data)
except (TypeError, AttributeError, UnsupportedOperation):
length = N
body = d
if getattr(body, 'tell', None) is not None:
# Record the current file position before reading.
# This will allow us to rewind a file in the event
# of a redirect.
try:
self._body_position = body.tell()
except (IOError, OSError):
# This differentiates from None, allowing us to catch
# a failed `tell()` later when trying to rewind the body
self._body_position = objec
if files:
raise NotImplementedError('Streamed bodies and files are mutually exclusive
if length:
self.headers['Content-Length'] = builtin_str(length)
else:
self.headers['Transfer-Encoding'] = 'chunked'
else:
# Multi-part file uploads.
if files:
(body, content_type) = self._encode_files(files, data)
else:
if data:
body = self._encode_params(data)
if isinstance(data, basestring) or hasattr(data, 'read'):
content_type = None
else:
content_type = 'application/x-www-form-urlencod
self.prepare_content_length(bo
# Add content-type if it wasn't explicitly provided.
if content_type and ('content-type' not in self.headers):
self.headers['Content-Type'] = content_t
self.body = body
@staticmethod
def _encode_files(files, data):
"""Build the body for a multipart/form-data request.
Will successfully encode files when passed as a dict or a list of
tuples. Order is retained if data is a list of tuples but arbitrary
if parameters are supplied as a dict.
The tuples may be 2-tuples (filename, fileobj), 3-tuples (filename, fileobj, contentype)
or 4-tuples (filename, fileobj, contentype, custom_headers).
"""
if (not files):
raise ValueError("Files must be provided.")
elif isinstance(data, basestring):
raise ValueError("Data must not be a string.")
new_fields = []
fields = to_key_val_list(data or {})
files = to_key_val_list(files or {})
for field, val in fields:
if isinstance(val, basestring) or not hasattr(val, '__iter__'):
val = [val]
for v in val:
if v is not None:
# Don't call str() on bytestrings: in Py3 it all goes wrong.
if not isinstance(v, bytes):
v = str(v)
new_fields.append(
(field.decode('utf-8') if isinstance(field, bytes) else field,
v.encode('utf-8') if isinstance(v, str) else v))
for (k, v) in files:
# support for explicit filename
ft = None
fh = None
if isinstance(v, (tuple, list)):
if len(v) == 2:
fn, fp = v
elif len(v) == 3:
fn, fp, ft = v
else:
fn, fp, ft, fh = v
else:
fn = guess_filename(v) or k
fp = v
if isinstance(fp, (str, bytes, bytearray)):
fdata = fp
elif hasattr(fp, 'read'):
fdata = fp.read()
elif fp is None:
continue
else:
fdata = fp
rf = RequestField(name=k, data=fdata, filename=fn, headers=fh)
rf.make_multipart(content_type=ft)
new_fields.append(rf)
body, content_type = encode_multipart_formdata(new_fields)
return body, content_type
通过对上面的代码简单分析可以发现,在处理body时,会判断是不是stream,其实这就跟我们上面说到的文件上传有关,如果使用了流,则会对这个上传的文件分块(chunk),然后计算文件的大小,并将 Content-Length 参数添加到请求头中,如果不使用流式上传,则会判断是否使用了files这个参数,如果使用了files参数,则又会将files中的文件放到请求报文中,指定 Content-Type=multipart/form-data,再进行请求发送,再这个过程中files跟data中的参数值会做合并,因此实现了再上传文件的同时,也能提交其他参数。
auth
auth这个参数其实我们很少用到,因为我们一般不会用到使用 HTTPBasicAuth 方式鉴权的请求,其预处理方法为 prepare_auth,核心代码如下:
def prepare_auth(self, auth, url=''):
"""Prepares the given HTTP auth data."""
# If no Auth is explicitly provided, extract it from the URL first.
if auth is None:
url_auth = get_auth_from_url(self.url)
auth = url_auth if any(url_auth) else None
if auth:
if isinstance(auth, tuple) and len(auth) == 2:
# special-case basic HTTP auth
auth = HTTPBasicAuth(*auth)
# Allow auth to make its changes.
r = auth(self)
# Update self to reflect the auth changes.
self.__dict__.update(r.__dict__)
# Recompute Content-Length
self.prepare_content_length(self.body)
要理解上述代码,其实就要了解 HTTPBasicAuth 的鉴权方式,在此处不做扩展,有兴趣的可以去翻阅 HTTP常用的几种认证机制
小结
自此,我们已经比较深入的了解了几个常见参数的处理方式,但是除了上面几个请求参数外,requests还支持一些比较特别的参数,在下面的章节中,我将简单介绍这几个参数的简单用法,不做深入讲解,有兴趣的同学可以去翻阅requests的官方开发文档
Requests中的特殊参数
timeout
timeout这个参数在之前讲解request对象时已经简单讲过,作用就是指定超时时间,下面我用一个具体的例子来演示其用法
"""
要求:现有一接口,需要验证其接口响应时间是否在500ms以上,如果超时,则要抛出 ReadTimeout 异常
"""
api_path = "/performance_test/sleep"
headers.update({"sleeptime": "3"})
with pytest.raises(ReadTimeout):
requests.get(url=urljoin(HOST, api_path), headers=headers, timeout=0.5)
一般我们很少单独设置connect和read的超时时间,更多时候我们关注的是整体的超时时间
verify
这个参数是用来为HTTPS请求验证SSL证书,默认是开启的,如果证书验证失败,则requests会抛出SSLError,一般我们在访问一个https请求时,会将verify设置为False
cert
我们也可以指定一个本地证书用作客户端证书,具体使用方法参考 客户端证书,这个参数我们极少用到,除非安全要求非常高。
stream
stream是一个比较特殊的参数,因为默认情况下,当我们发出请求后,响应报文会被立即下载,我们可以通过设置 **stream=True**的方式来推迟响应报文的下载,直到访问 Response.content 属性,在此之前仅有响应头被下载了,连接保持打开状态,这种情况一般用于我们需要精细的手动处理响应报文,否则不推荐使用此参数,因为这会导致requests无法释放连接到连接池,带来连接效率低下的问题。
hooks
hook顾名思义,就是用来设置一个钩子函数,做一些额外的操作,requests提供了一个可用的钩子 response 来让我们自定义部分请求过程或者信号事件处理,下面给出一个示例代码
def hook_function(response, *args, **kwargs):
print(response.headers)
def request_by_hook():
url = "http://www.httpbin.org/get"
payload = {
"name": "wickTu",
"age": 27,
}
requests.get(url=url, params=payload, hooks=dict(response=hook_function))
>> {'Date': 'Thu, 04 Mar 2021 03:46:57 GMT', 'Content-Type': 'application/json', 'Content-Length': '376', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
通过上面的例子可以看出,我们使用回调函数hook_function来实现了对响应头的打印,当然,这只是个很简单的例子,我们可以使用hook函数来实现诸如 日志记录,响应报文解析等各种功能,具体就看你脑洞有多大啦。
proxies
这个参数在我们写爬虫时太有用了,通过指定代理,我们可以绕开ip封锁,端口封锁等问题,使用起来也很简单,示例代码如下:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
allow_redirects
这个参数要求我们是否允许自动重定向,默认为True,但是有些特殊场景下,我们是不允许重定向,下面我以一个具体的例子来展示这个参数用法:
"""
背景:oppo平台IT部的sso提供了多种登录方式,其中protal项目使用了通过回调url来登录,通过对sso的logini接口抓包分析,发现此login接口在调用时,会将token放到response heaers中,然后会重定向到其他接口,如果直接调用此接口,则无法拿到token,因此我们需要使用allow_redirects=False来获取token
"""
import requests
def sso_by_callback_url(username: str, password: str, from_url: str):
url = "https://t-ssov2.myoas.com/sso/user/login"
headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
params = {
"mode": "",
"login_type": 0,
"loginTypePage": 1,
"username": username,
"password": password,
"from_url": from_url
}
resp = requests.post(url=url, params=params, headers=headers, allow_redirects=False)
return "Bearer " + resp.headers['Set-Cookie'].split(";")[0].split("=")[1]
if __name__ == '__main__':
data = {
"username": "",
"password": "",
"from_url": ""
}
token = sso_by_callback_url(**data)
print(token)
小结
以上讲解的几个参数,其实我们都很少用到,但是了解他们,对我们编写http请求有很大的帮助,建议学习。
自定义HTTP请求动词
除了HTTP提供的请求方法外,我们也可以定制自己的HTTP动词,比如我自己写了一个接口,要求使用 _**TUTU **_这个请求方式,那我们可以使用如下方式来搞定:
import requests
r = requests.request("TUTU", url="http://xxxxx", data=data)
自定义传输适配器
Transport Adapter 其实我们极少会用到,requests自带了一个传输适配器 HTTPAdapter,此适配器也是基于urllib3实现,下面我用一个具体的例子来介绍如何使用:
"""
csc业务线的同学可能见过,使用老的uat自动化测试框架时,在 HttpClient 类的__init__()中有如下一段代码
"""
def __init__(self):
self.session = requests.Session()
# adapted ssl version
self.session.mount('https://', SSLAdapter(PROTOCOL_TLSv1))
""""
其实上面这段代码,就是用到了一个SSL适配器,因为当时我在写代码时发现,正常使用requests访问paas环境接口时,一直会返回 SSLVersionError,这就说明我们使用的ssl证书跟requests自带的ssl证书版本不匹配,通过测试,将本地ssl证书版本改为TLSv1就可以正常访问接口,因此才会有上面那一段代码
""""
总结
Requests库正如官方文档介绍的一样: 是唯一一个非转基因的Python HTTP库,人类可以安全享用。requests库强大的能力和令人叹为观止的模块化设计,使得我们在发送http请求时,如呼吸一样简单,但是我们在享受方便的同时,也要去了解这背后的复杂,更建议大家去深入了解下HTTP协议并认真阅读requests官方文档,这将更加有助于我们自己的提升,谢谢!