悲剧的开始
2023.8.17 早上 7:30 刚睡醒,都没来得及洗漱,手机上就收到了公司运维平台发的告警
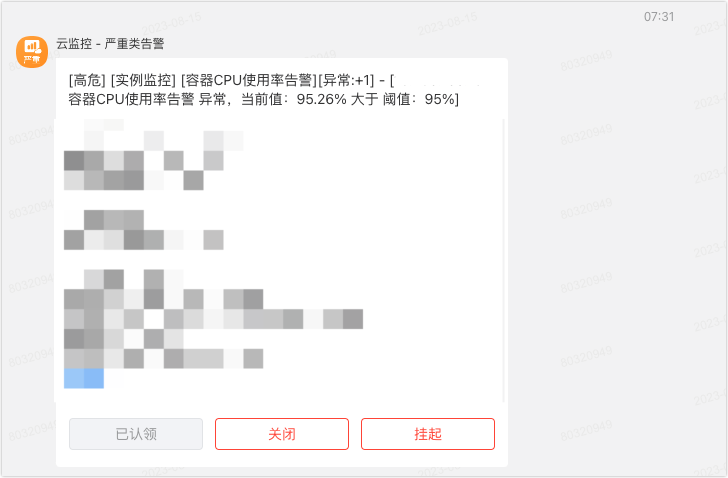
有一台服务器 cpu 使用率超过 95%了,当时没在意,以为上面正在跑任务(这个服务器上面部署的是我们自己开发的自动化测试平台,用例执行引擎是 Jmeter,后端开发框架是 springboot)。等我收拾完准备出门上班的时候,发现手机上又双收到了 2 条告警,cpu 使用率没有下去,当时在想是不是自动化任务跑的时间比较长,再等等。。。然后就骑车出门了。
8:30 在地铁上打开手机看了下,发下又双叒收到了告警,我擦,怎么没完了,隐隐有种不好的预感。同时在 vx 群里,老板也在艾特我,问我为啥一直在告警,可是我也母鸡啊。。。

8:50到公司,打开 IM 工具一看,好家伙,又双叒叕多了好几条告警,上运维平台看了下服务器监控,瞬间血压就上来了。。。
问题出现
我次奥啊,这台 8C16GB 服务器的 cpu 使用率从8.14 开始,蹭蹭蹭的往上涨啊,一点回落的迹象都没有。
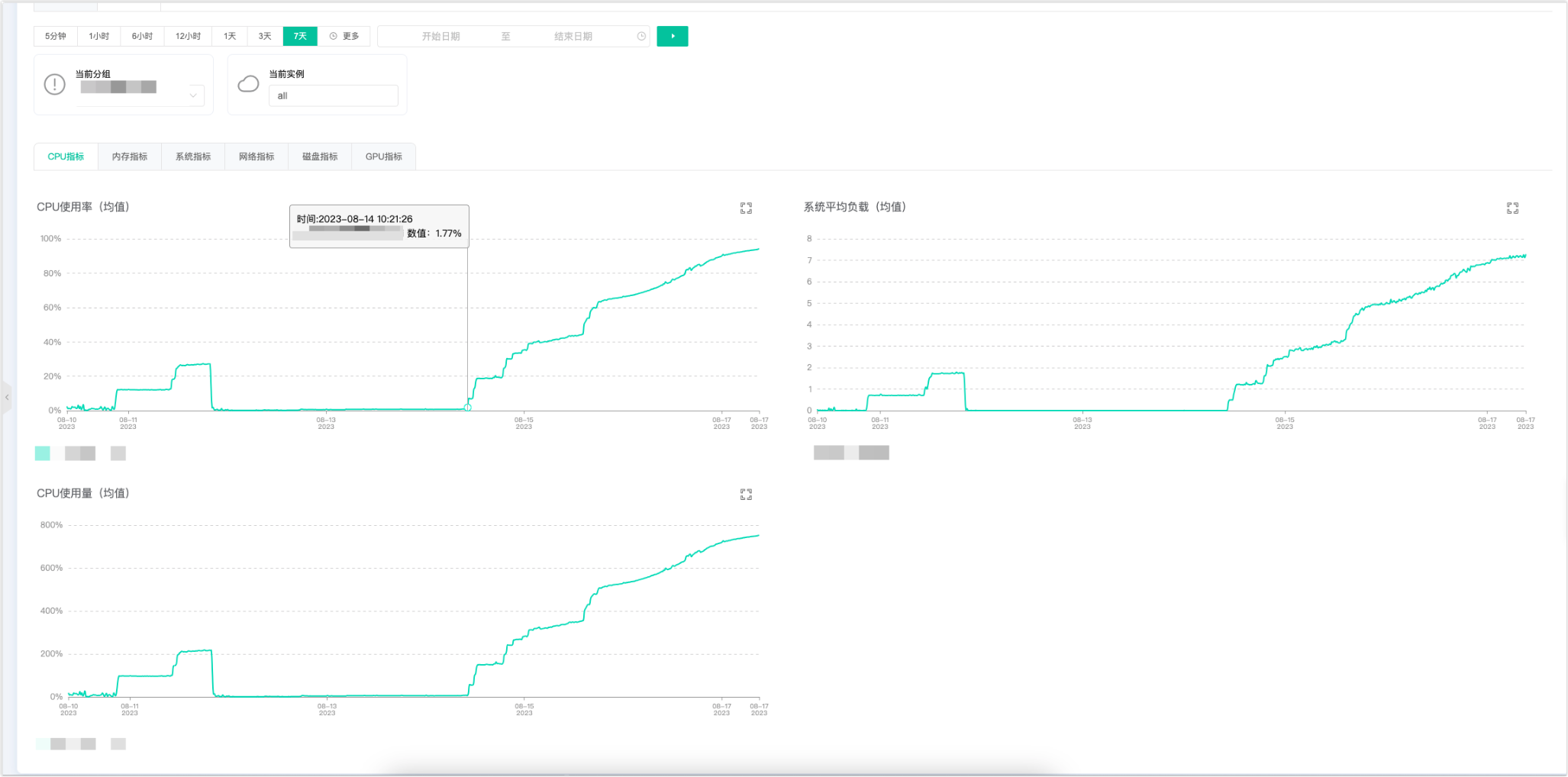
同时看了下最近一周的监控记录,发现 cpu 使用率在 8.10就开始增长了,8.11回落了,然后过了一个周末,从 8.14 开始就跟吃了炫迈一样,根本停不下来。结合这个服务的发版记录,猜测可能是 8.10 发布的那个版本有问题,导致8.11当天出现了 cpu 使用率上涨的问题。因为8.11那天发现 8.10 发布的版本有问题,8.11 晚上又发布了一个 hotfix 版本,而且那天正好是周五,所以周末两天都没人用自动化测试,cpu 使用率就非常低。8.14周一上班了,大家开始做自动化测试了,问题就开始出现了。
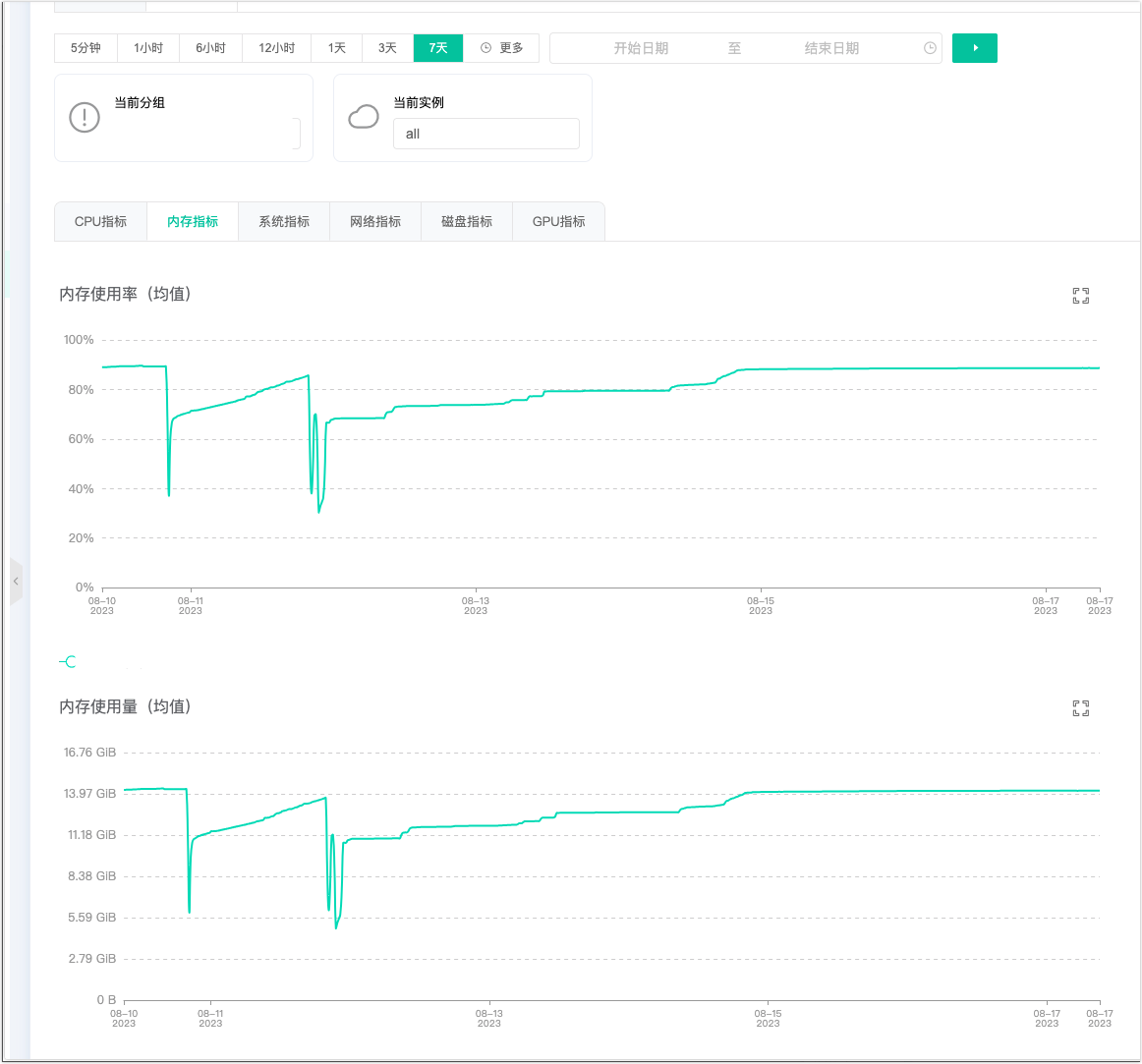
再看下内存使用率,差点一口气没上来,16GB 的内存用了 14GB,这特喵的是内存泄露了吧,而且 cpu 使用率还高的吓人,但是当时看了下服务器上的日志,并没有几个任务再跑,说明有其他的线程可能在狂占 cpu。
初步定位
就在我对着这个监控数据抓狂的时候,陆续又收到了其他测试同学的反馈:自动化用例执行了结果出不来,刷新页面偶尔出现了“上游服务器无响应” 等等问题。得!赶紧先上服务器捞一把数据,然后把服务器重启了先,不然等会儿就真的要宕机了。
登录服务器之后,首先要看下 cpu 和内存使用率是不是真的高到离谱,用 top 命令一看确实不行了(运维平台的监控偶尔抽风不准)。
分析 GC 情况
执行命令
jstat -gcutil 339 1000 100 > gc.log
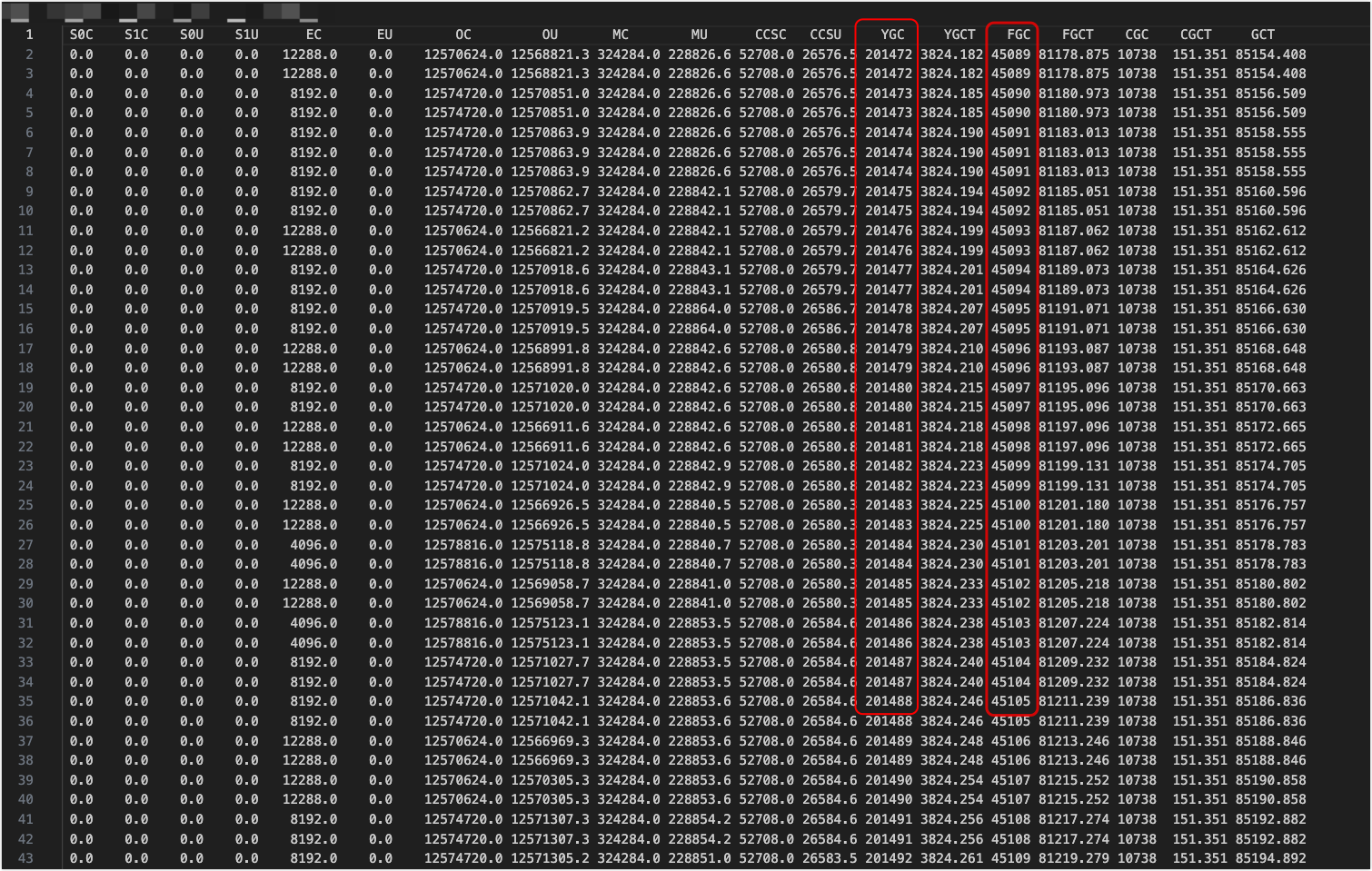
好家伙,youngGC 了 20 多万次,fullGC 4万多次,基本每2s 进行一次 GC,这内存不爆才有鬼了。
再看下 JVM 配置
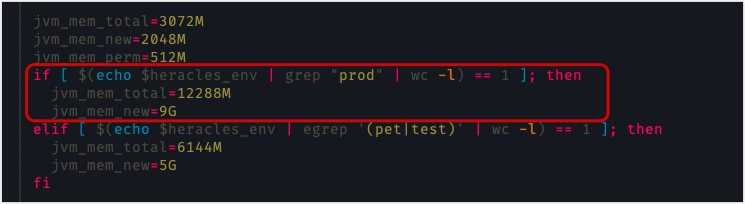
可以,很 6,jvm 直接给了 13GB,哪个天杀的教他们这么配置 heap 的!

分析对象直方图
执行命令
jmap -histo 339 > histo.txt
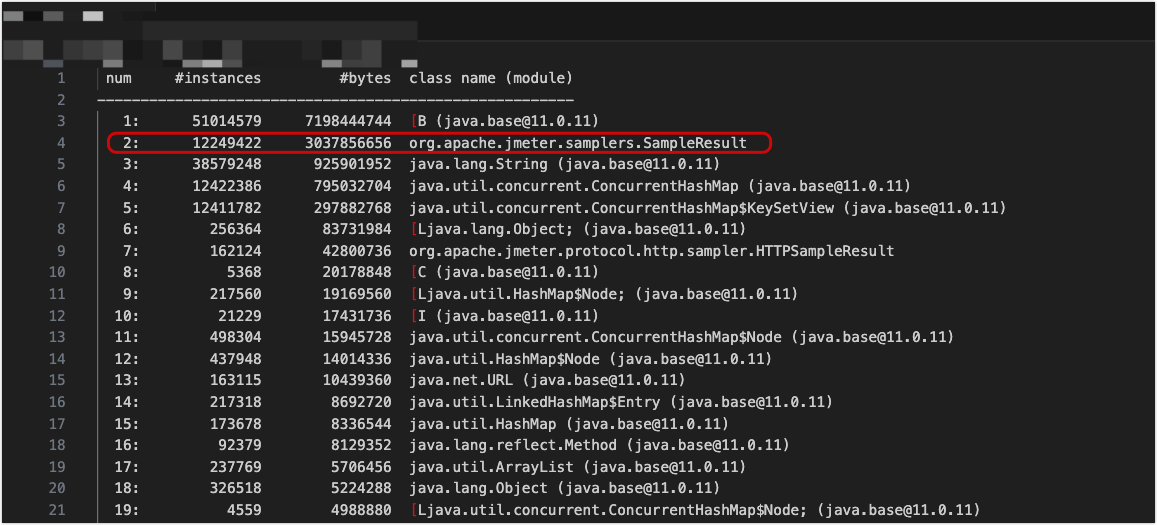
很秀,光 org.apache.jmeter.samplers.SampleResult 对象都有 1224w+ 了,占用了 3G 内存,熟悉 Jmeter 的同学都知道,这个对象是 Jmeter 用来存储采样器结果的(不知道的可以去百度一下)。TM 什么样的测试用例能跑出来这么多对象,而且还没释放,说明这种用例还在执行,那其实就从侧面印证了 cpu 使用率为啥居高不下。
光凭这两个数据,还是没法准确分析出问题出在哪里,所以最后只能祭出终极大招:分析内存快照
分析内存快照
执行命令
jmap -dump:format=b,file=heapdump.bin 339 > heapdump.bin
光执行这个命令都用了 5 分钟,生成的原始文件 16GB,然后使用 zip 压缩以下再下载。
zip heapdump.bin.zip heapdump.bin
不要幻想用 tar 去压缩,tar 压缩效率很低,而且压缩完成的文件跟原始文件差不多大。zip压缩完成后得到的 heapdump.bin.zip 有 1.7GB,下载都用了 20min(U1S1,从生产环境的服务器下载东西是真的慢......)
这个时候是不是该分析这个文件了?错!分析个毛线啊,赶紧重启服务器啊,不然等会彻底宕机了,我们就凉凉了。因为这个服务是双实例部署,所以使用串行重启,网关那边做了负载均衡,对于用户来说基本无法感知到服务被重启了(不排除运气不好的人,请求正在被重启的服务器上执行,则就会出现 504 的问题)。
服务器重启完成后,再看下 cpu 使用率,发现终于降下来了,内存不用看,13GB 的堆内存还是挺抗打的。但是,如果现在不解决,cpu 和内存飚上去是迟早的事情,可能都等不到我们下次发版本了,估计本周末就能 gg。

服务重启完了,赶紧分析下快照文件吧,我用的工具是 MAT,然后就发现了一个悲剧的事情,这个 bin 文件有 16GB,我电脑内存才 16GB,MAT 默认的内存是 2GB,打开这个文件转圈转了 10min 都没处理完。先把mat 内存改下吧。修改 mat 安装目录下的 /Applications/mat.app/Contents/Eclipse/MemoryAnalyzer.ini 文件中的 -Xmx 配置为 8g
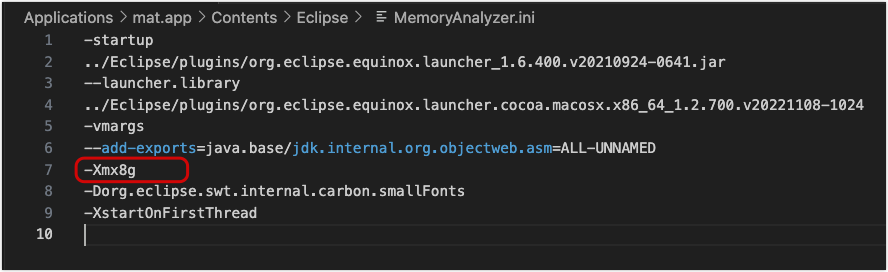
然后重新打开这个bin 文件,这次转圈转了 5min 才好。
内存泄露分析
先看下 mat 生成的 leak suspects 报告,看下是不是有疑似内存泄露的问题。
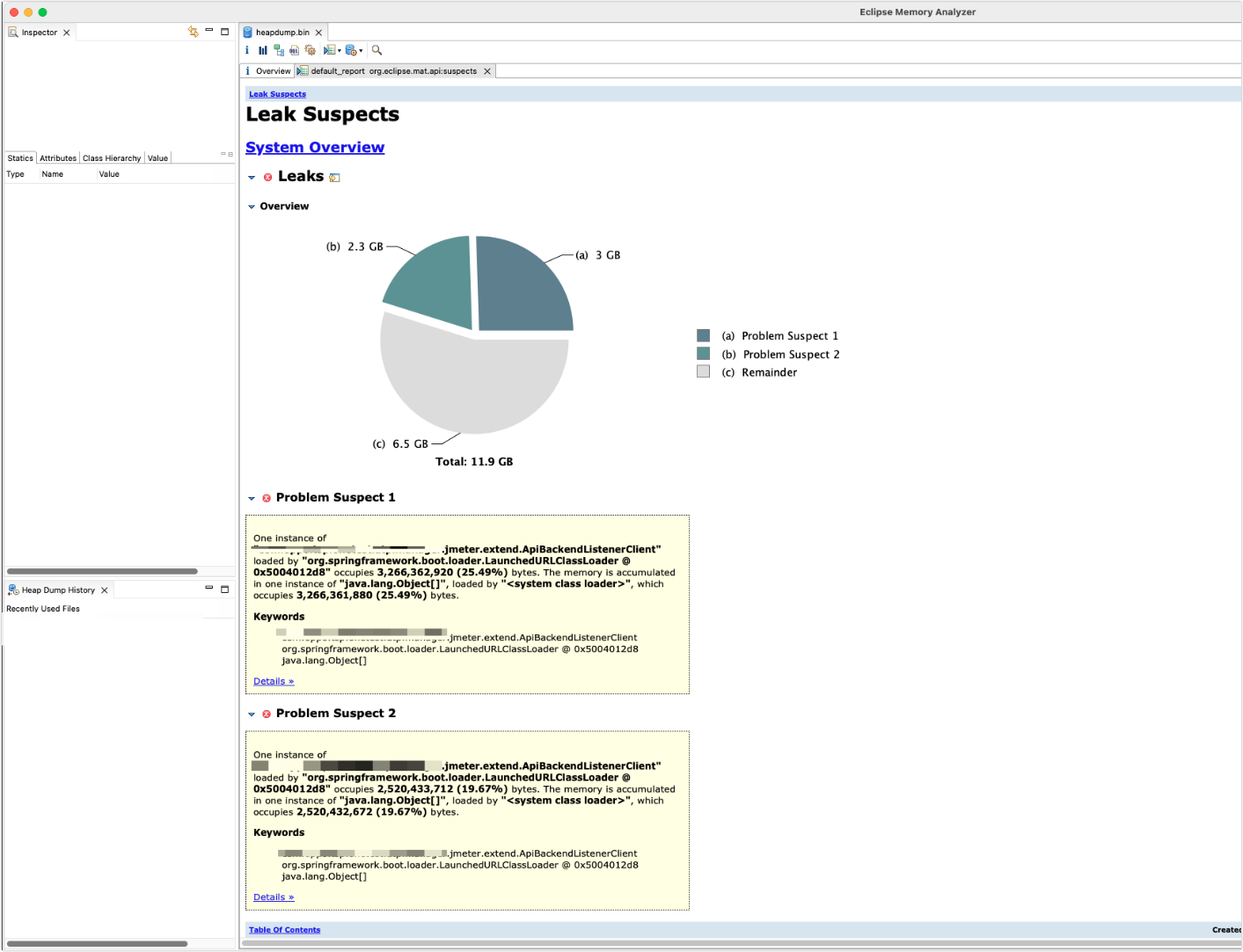
emm......漏就漏了吧,不漏才见鬼了
从上面的报告可以看到,有个疑似内存泄漏的对象:ApiBackendListenerClient
这个类是我们服务自己写的类,继承了 Jmeter 的 AbstractBackendListenerClient,是一个监听器类,作用是收集 Jmeter 执行过程中的采样器结果。这个类有三个重写的方法
-
setupTest: 允许开发者在测试开始之前进行一些初始化操作,例如建立与后端系统的连接、准备发送数据等,此方法只会调用一次。
-
handleSampleResults: 每个线程组的每个请求都会生成一个样本结果,样本结果包含了该请求的响应时间、响应码、响应数据等信息。handleSampleResults方法会接收这些样本结果,并进行处理。可以在这个方法中编写代码来将样本结果存储、发送到数据库、生成报告等。通过重写handleSampleResults方法,可以自定义后端监听器在测试期间如何处理样本结果。这个方法会频繁调用,即 Jmeter 每发送一次请求,此方法都会被调用一次。
-
teardownTest: 测试结束后的操作,一般用于发送数据,清理数据等等,此方法只会调用一次。
既然都找到自己的类了,那就先看下为啥这个类会持有这么多 SampleResult 对象吧。接下来对代码进行分析。
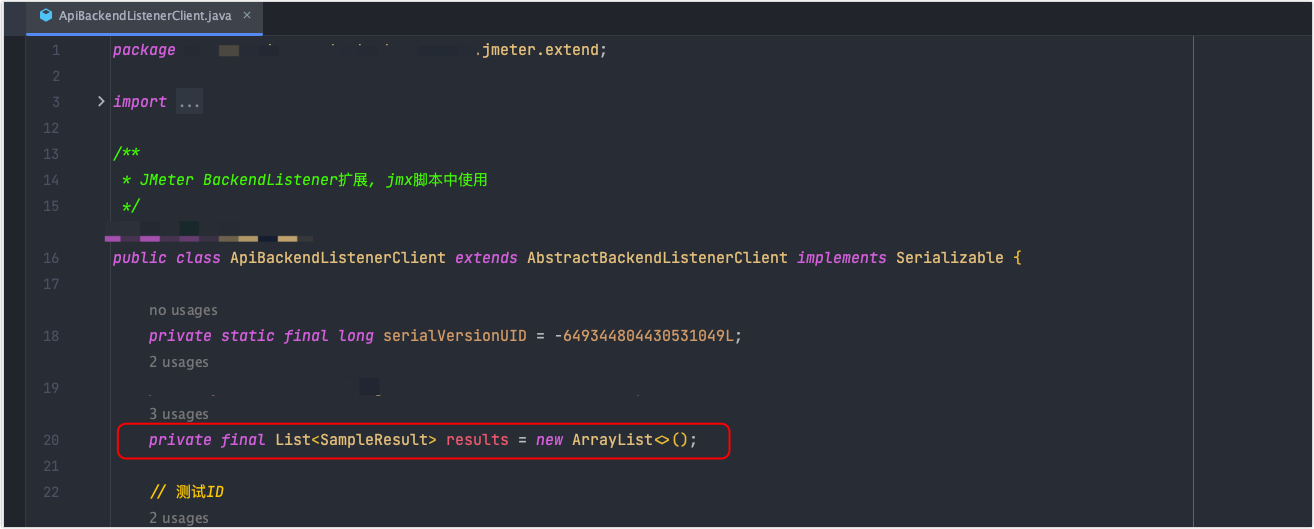
在这个类中,创建了一个 List<SampleResult> results 来存储测试过程中产生的采样器结果,测试完成后,会把这个 list 清空。既然现在出现了这么多对象,那就说明由以下两种情况导致:
- 还没有测试完成,testdownTest 方法没有调用
- result.clear()没执行,原因可能是上面的方法执行异常
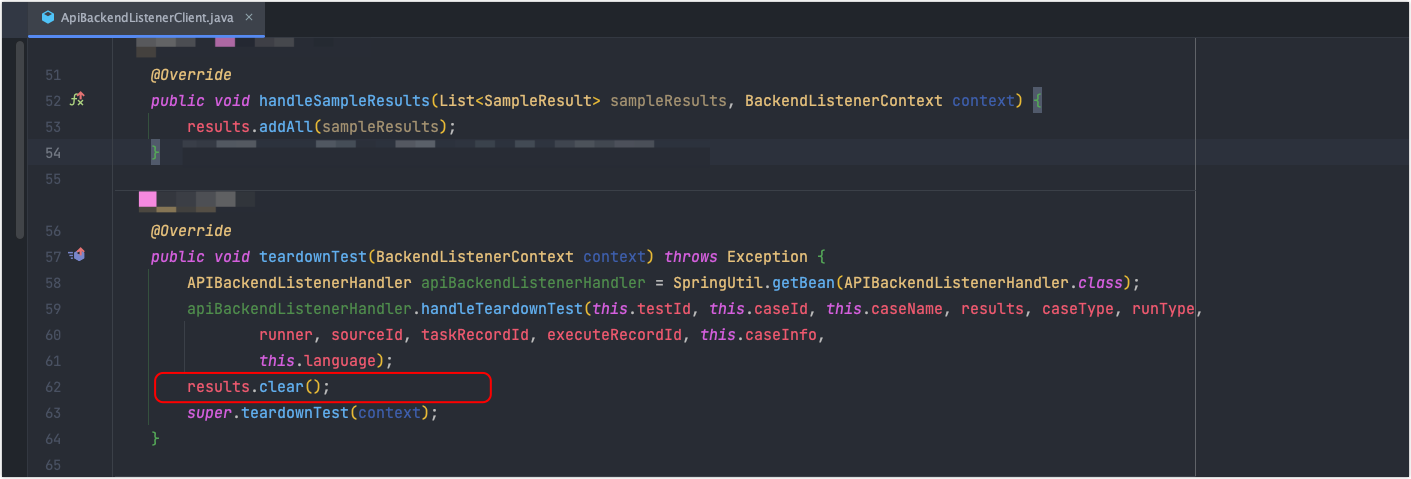
没测试完成这个原因有点扯淡,刚才看服务器日志发现都没几个任务在跑,不可能产生 1224w+ 个对象,所以有可能就是 teardownTest 里面的 handlerTeardownTest 方法异常了,导致下面没有清理对象,所以重点是先看下这个方法是不是哪里有问题。但是啊,事实证明我的推测是错误的...
在对这个handlerTeardownTest方法翻来覆去看了一个多小时,都没发现哪里有问题,该做异常处理的地方都做了,讲道理,应该会执行result.clear(),难道是 jmeter 抽风了,这个 teardownTest 根本就没有被调用?那如果没有被调用,就说明测试没结束,这样就说的通了:还有测试任务在进行,虽然服务器上日志显示没啥任务再跑,但是保不齐 Jmeter 的执行线程还在跑其他任务,而且这个任务是没有被我们服务正常处理掉的,因为我们为了保证用例(对应一个 hashTree,即 jmx 脚本)不能占用太长的时间,所以做了限制,当一条用例执行超过 5min 时,会强行结束,并把用例执行结果标记为超时。
事已至此,那就只能分析这个 SampleResult 对象为什么会创建这么多,而不进行释放,检查
此对象引用关系
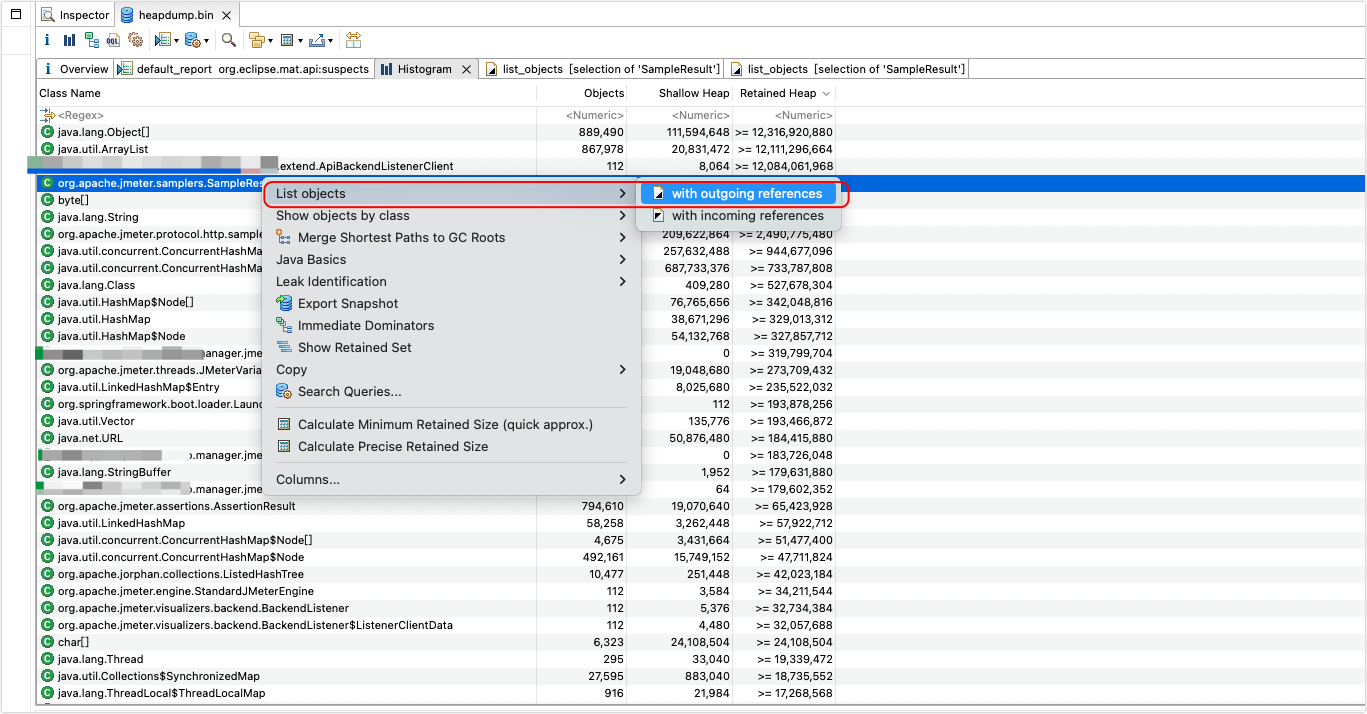
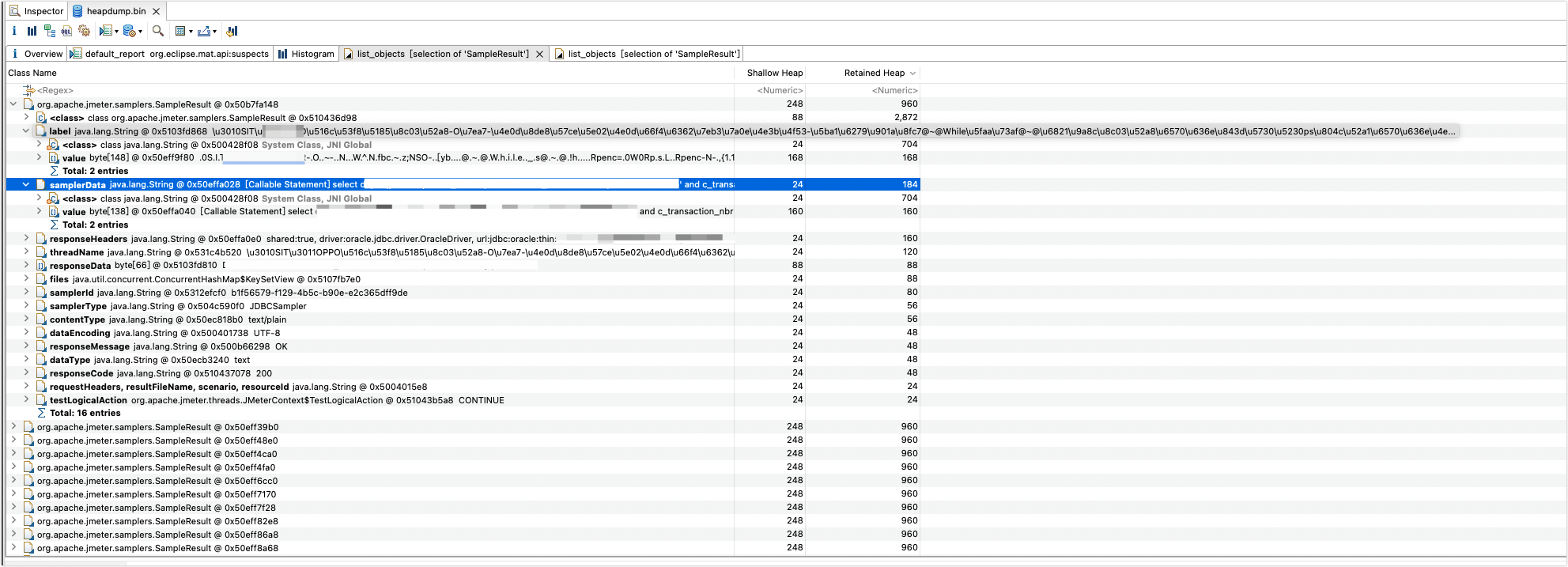
可以看到此时正在执行一个 jdbc 采样器,对采样器 label 进行 unicode 转中文可以看到内容是:
【SIT】xxxxxxxxx@~@While循环@~@校验调动数据 xxxxx-第113069次循环
(上面的 xxx 就是用例相关内容,此处做了脱敏)其中,第113069次循环 表示次用例可能是放在了一个 while 控制器中,但是 while 控制器是有固定的退出逻辑,如果到达指定时间没有满足条件,则会自动退出循环,一般来说不可能出现 11w+次的循环。在这里解释下为啥我说是进行了 113069 次循环,这是因为我们在对 Jmeter 做二次开发的时候,在生成报告时需要展示循环控制器下面采样结果,为了区分是哪个循环控制的,所以使用特殊分隔符 @~@ 来标记,后面的 113069 就是循环次数,大家也可以在 Jmeter 中添加一个 查看结果树 组件来看下效果。
同时结合一个线上缺陷
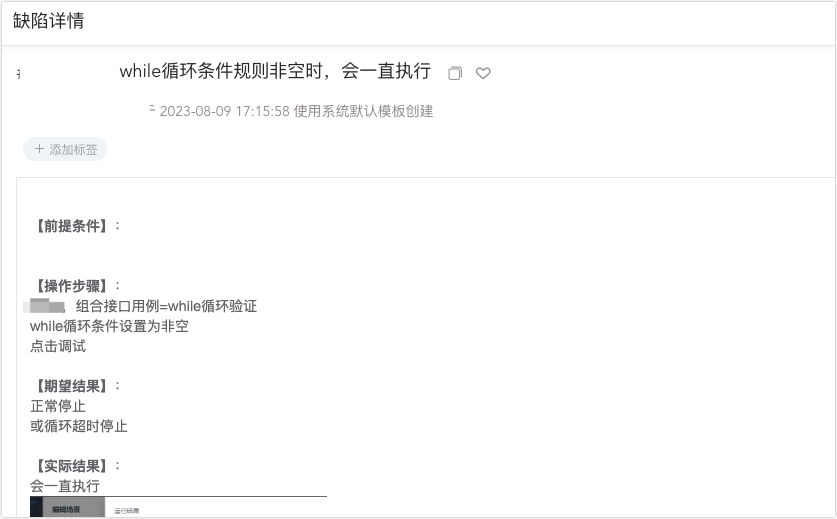
我猜测,这个 bug 根本就没修复好,或者修复了非空判断的问题,但是改出来了另一个 bug。
事已至此,无需多言,让改 bug 的人再去检查代码,最后发现确实是在生成 while 循环控制器的条件时,代码错误,导致这个 while 控制器无法退出。虽然有用例执行超时 5min 的限制,那也只是终止了调用 StandardJMeterEngine.run 方法的线程,Jmeter 在实际执行时还会创建子线程来执行采样器,这就导致了虽然用户看到了用例超时,但是这个循环控制器根本就停不下来,然后不停的调用 handleSampleResults方法,往 results里面塞数据,导致这个 list 膨胀的非常大。再加上加了 while 控制器的用例很多,大家都跑用例,导致这种线程停不下来,把服务器累个半死,内存也没法释放。
最终,这个问题被修复了,修复方法很简单,在生成 while 控制器循环条件的时候加一个小括号就行,上次修复 bug 的时候漏了这个小括号,导致 while-true 了。欸,心累啊。。。
总结
这次事故根本原因就是开发在编写代码时没有对自己写代码做充分自测,并且没有评估到这种改动会造成什么样的影响,在我工作这么多年以来,这基本是一个无解的问题,只能说:各安天命吧!
写在最后的话
其实整篇文章看完,有些同学可能会嗤之以鼻,说:直接装一个 arthas,看下 dashboard 里面 RUNNERABLE 状态的线程,不就很快找到原因了么,哪有这么麻烦。但是现实情况是:
- 生产环境外网隔离,无法安装这类软件。
- arths 在注入 jvm 时,可能会导致 jvm 中的线程出现挂起的情况,导致用户操作失败。
- 当时服务器已经非常卡了,我在执行 jstack 命令时都出现了几次失败的情况,更别说这种重量级软件运行了。
所以啊,还是得学会用 JDK 自带的工具来分析问题,并且写代码的时候长点心吧!
本文省略了其他分析过程,因为那部分分析内容涉及到敏感代码和数据。
终。。。
